Book chapters
|
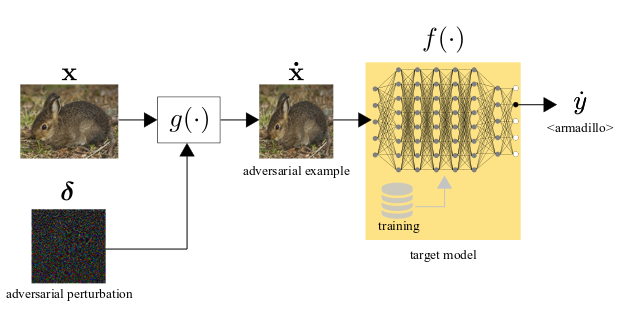
Chapter 15 - Visual adversarial attacks and defenses C. Oh, A. Xompero, A. Cavallaro In Advanced Methods And Deep Learning In Computer Vision, Editors: E. R. Davies, Matthew Turk, 1st Edition, Elsevier, pages 511-543, November 2021. [abstract] [chapter] [bibtex] [webpage] |
Journals
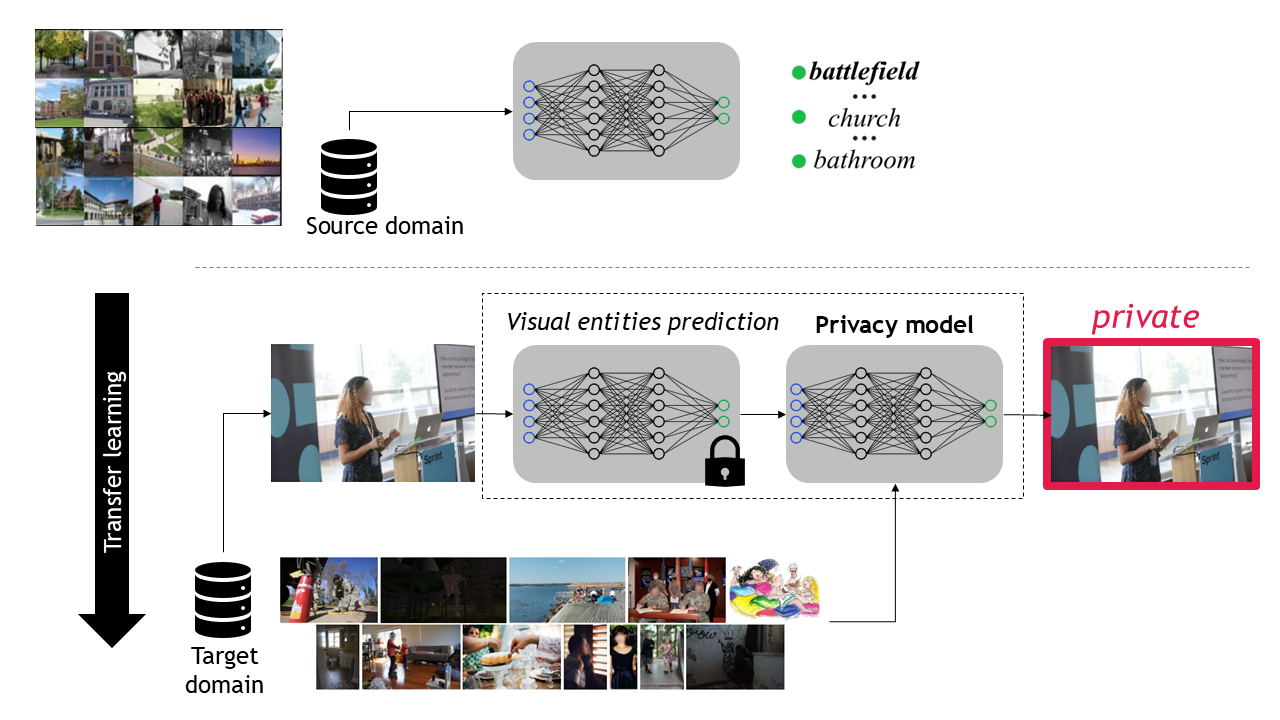 |
Learning Privacy from Visual Entities A. Xompero and A. Cavallaro Proceedings on Privacy Enhancing Technologies (PoPETs), vol. 2025, n. 3, pp. 1-21, March 2025 [abstract] [paper] [arxiv] [bibtex] [code] [data] [trained models] |
|
|
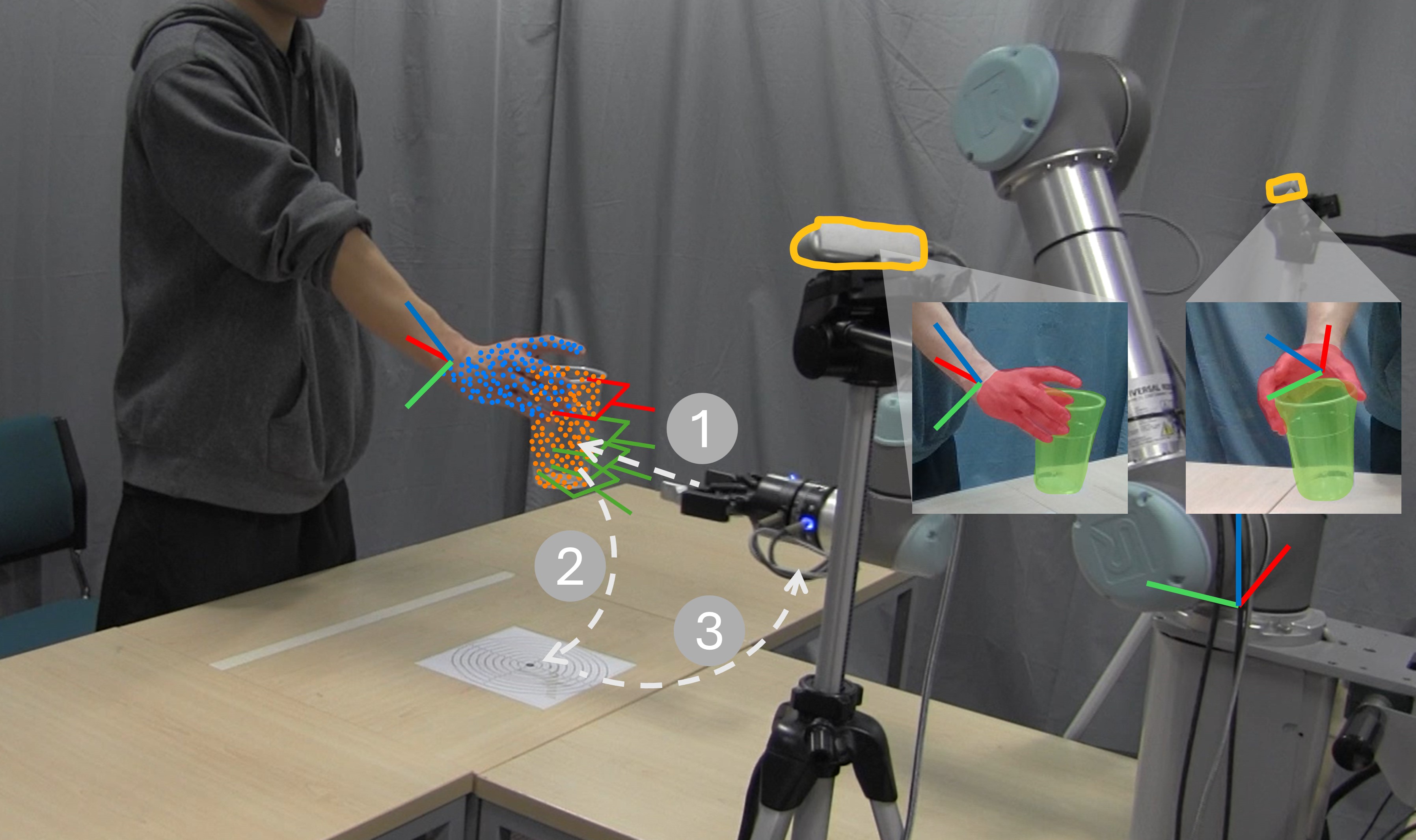
Stereo Hand-Object Reconstruction for Human-to-Robot Handover Y. L. Pang, A. Xompero, C. Oh, A. Cavallaro IEEE Robotics and Automation Letters, Vol.10, n.6, June 2025 To be presented at IEEE/RSJ Int. Conf. Intell. Robots and Systems (IROS), Hangzhou, China, 19-25 October 2025 [abstract] [paper] [arxiv] [bibtex] [code] [webpage] |
|
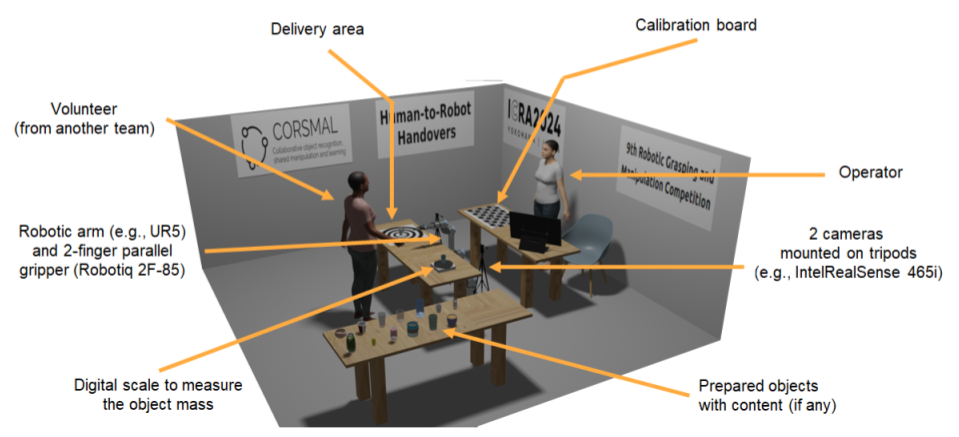 |
Robotic Grasping and Manipulation Competition at the 2024 IEEE/RAS International Conference on Robotics and Automation Y. Sun, B. Calli, K. Kimble, F. wyffels, V. De Gusseme, K. Hang, S. D’Avella, A. Xompero, A. Cavallaro, M. A. Roa, J. Avendano, A. Mavrommati IEEE Robotics & Automation Magazine, Competitions, vol. 31, n. 4, pp. 174-185, December 2024. [abstract] [paper] [bibtex] [webpage] |
|
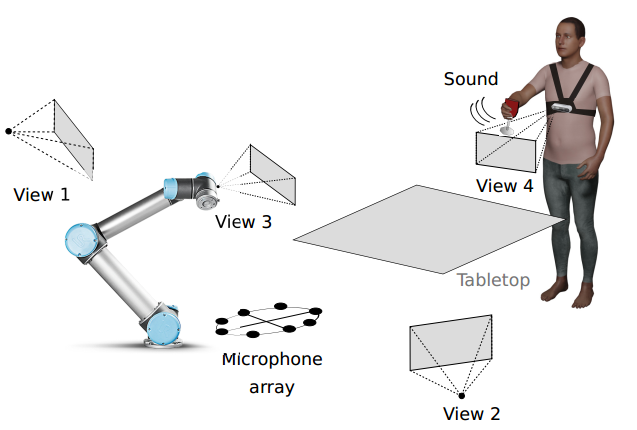 |
The CORSMAL Benchmark for the Prediction of the Properties of Containers A. Xompero, S. Donaher, V. Iashin, F. Palermo, G. Solak, C. Coppola, R. Ishikawa, Y. Nagao, R. Hachiuma, Q. Liu, F. Feng, C. Lan, R. H. M. Chan, G. Christmann, J. Song, G. Neeharika, C. K. T. Reddy, D. Jain, B. U. Rehman, A. Cavallaro IEEE Access, vol. 10, 2022. [abstract] [paper] [arxiv] [bibtex] [webpage] |
|
|
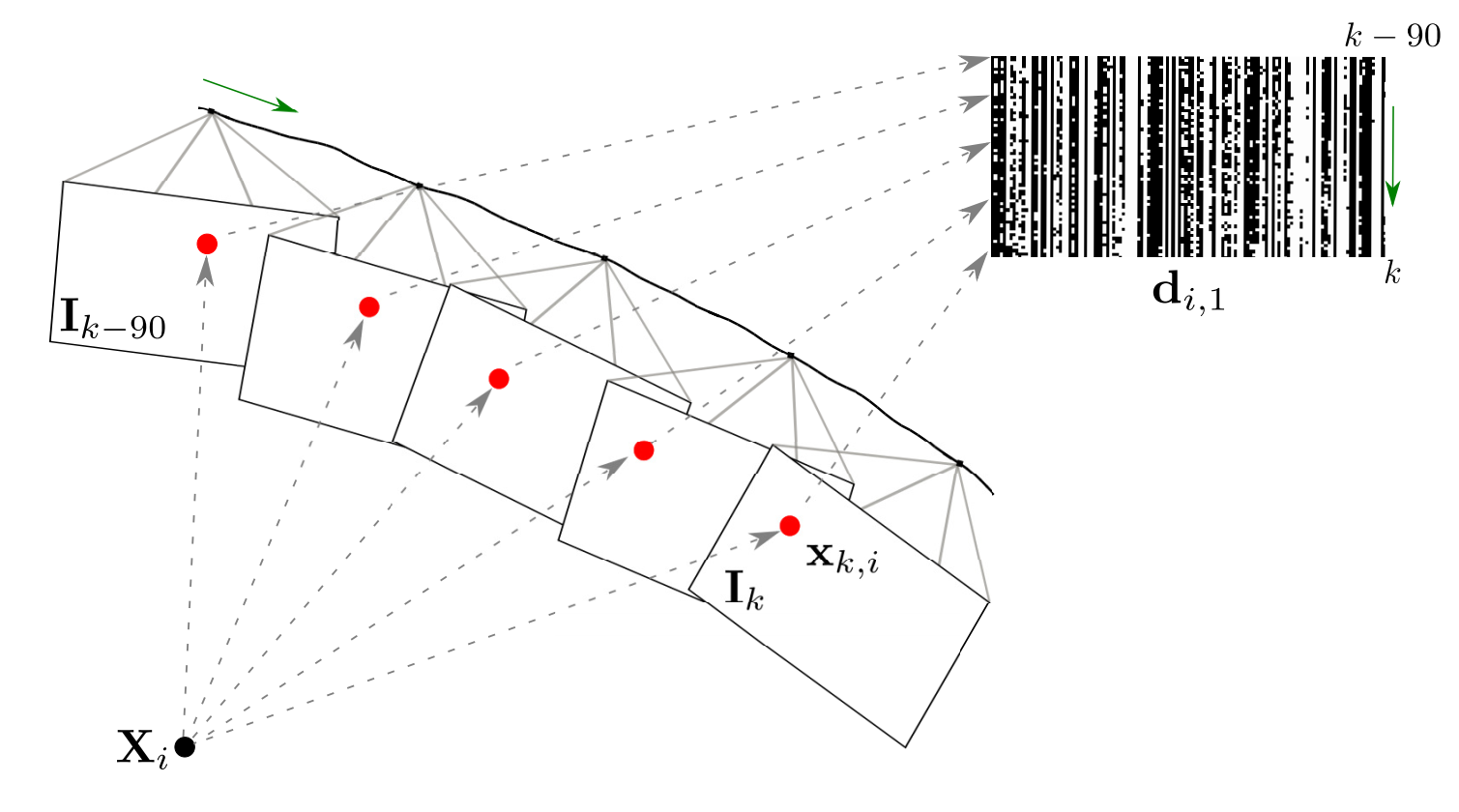
A spatio-temporal multi-scale binary descriptor A. Xompero, O. Lanz, and A. Cavallaro IEEE Transactions on Image Processing, vol. 29, no. 1, pp. 4362-4375, Dec. 2020. [abstract] [paper] [pre-print] [bibtex] [webpage] |
|

|
Benchmark for Human-to-Robot Handovers of Unseen Containers with Unknown Filling R. Sanchez-Matilla, K. Chatzilygeroudis, A. Modas, N. Ferreira Duarte, A. Xompero, P. Frossard, A. Billard, and A. Cavallaro IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1642-1649, Apr. 2020 [abstract] [pdf] [webpage] [bibtex] [code] [video] |
|

|
An On-line Variational Bayesian Model for Multi-Person Tracking from Cluttered Scenes S. Ba, X. Alameda-Pineda, A. Xompero, and R. Horaud Computer Vision and Image Understanding, 2016 [abstract] [pre-print] [bibtex] [video] |
Conferences
 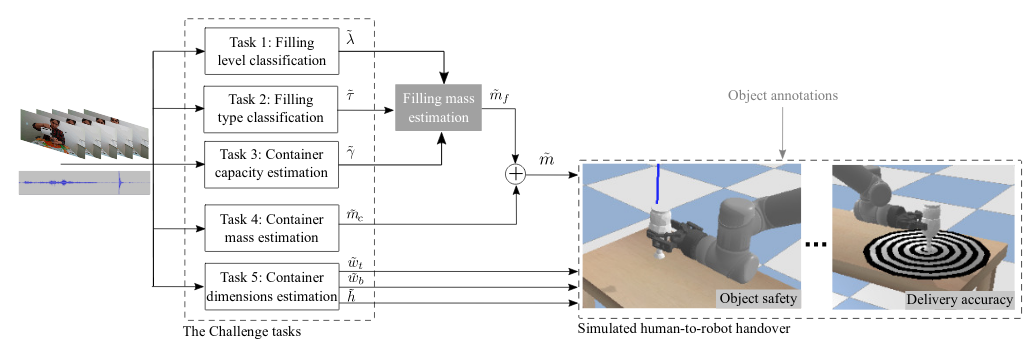 |
Audio-Visual Object Classification for Human-Robot Collaboration A. Xompero, Y. L. Pang, T. Patten, A. Prabhakar, B. Calli, A. Cavallaro IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Singapore and Virtual, 22-27 May 2022. [abstract] [paper] [arxiv] [challenge webpage] [bibtex] |
|
|
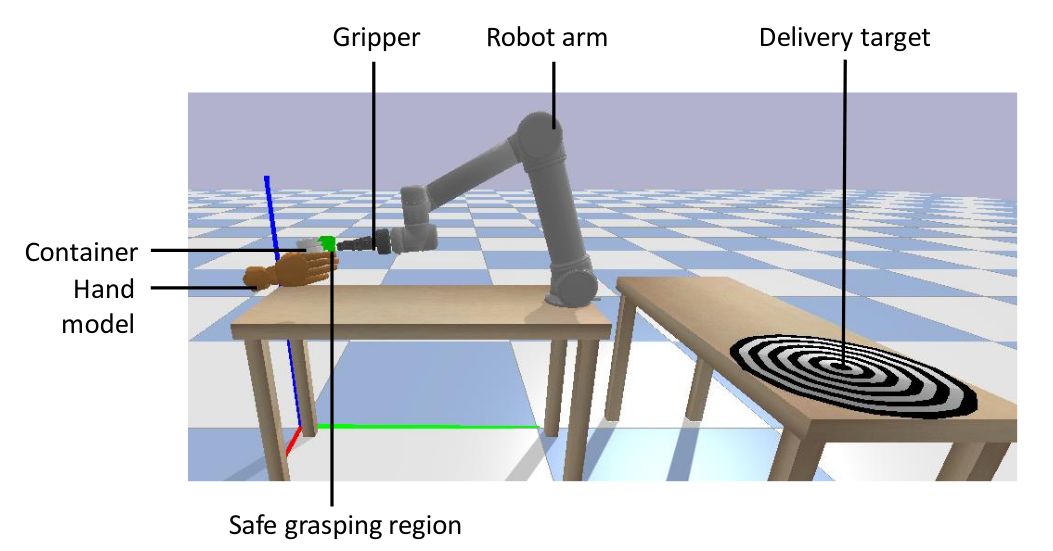
Towards safe human-to-robot handovers of unknown containers Y. L. Pang, A. Xompero, C. Oh, and A. Cavallaro IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Virtual, 8-12 Aug 2021. [abstract] [paper] [arxiv] [webpage] [bibtex] |
|
|
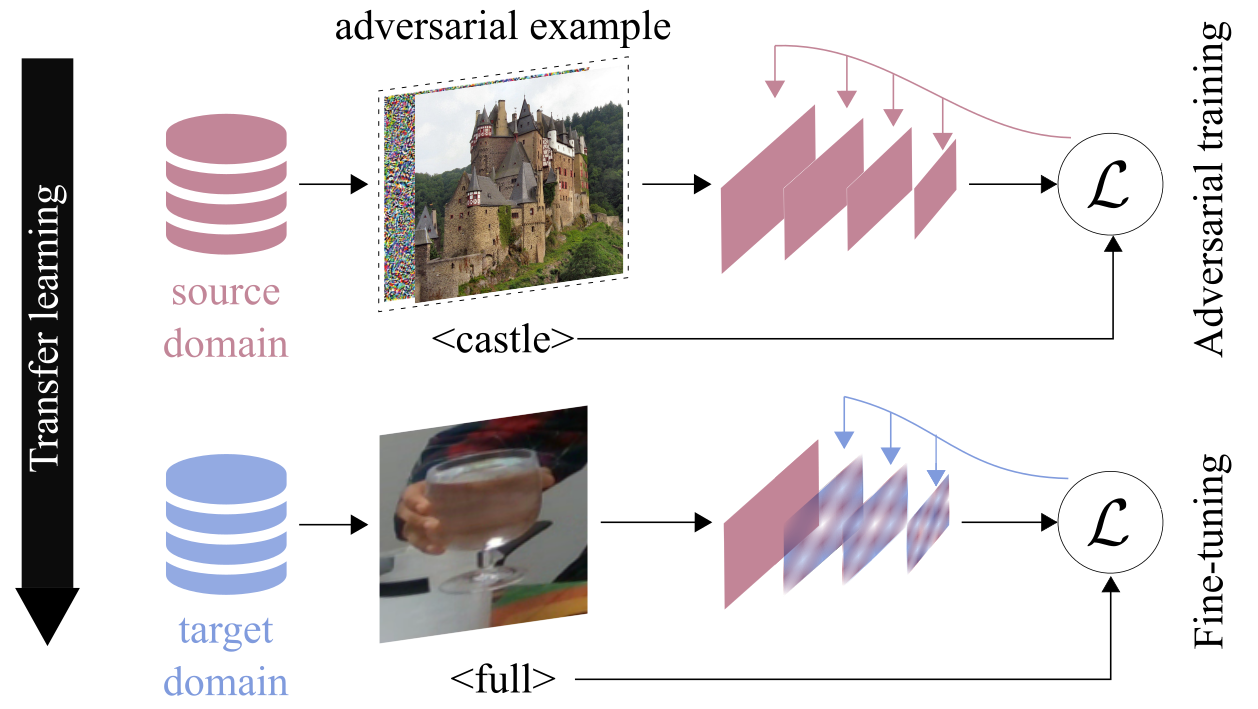
Improving filling level classification with adversarial training A. Modas, A. Xompero, R. Sanchez-Matilla, P. Frossard, and A. Cavallaro IEEE International Conference on Image Processing (ICIP), Anchorage, Alaska, USA, 19-22 Sep 2021. [abstract] [paper] [arxiv] [webpage] [bibtex] [data] [models] |
|

|
Audio classification of the content of food containers and drinking glasses S. Donaher, A. Xompero, and A. Cavallaro European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23-27 August 2021. [abstract] [paper] [arxiv] [webpage] [bibtex] [code] [data] [data2] [models] |
|
|
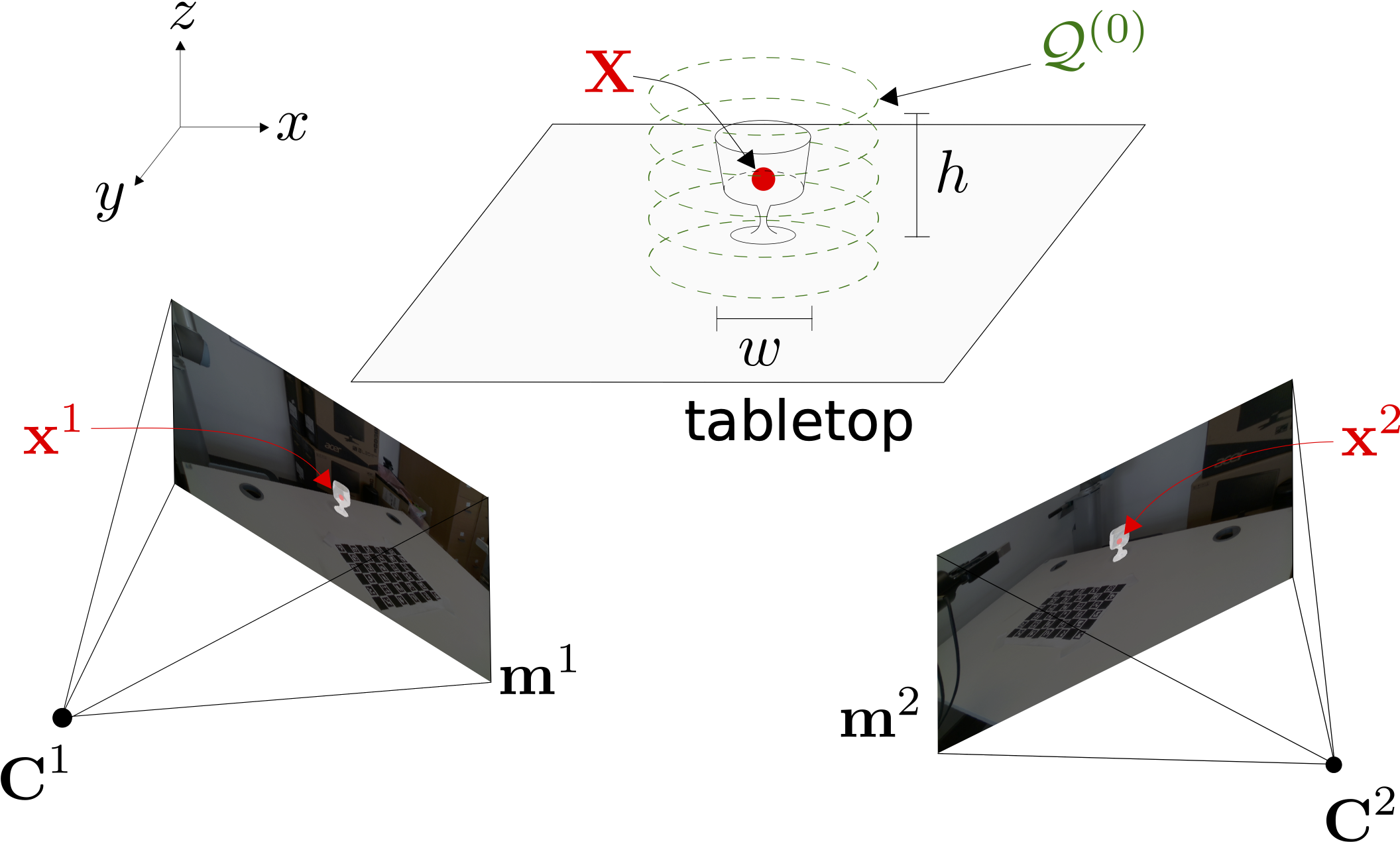
Multi-view shape estimation of transparent containers A. Xompero, R. Sanchez-Matilla, A. Modas, P. Frossard, and A. Cavallaro IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4-8 May 2020 [abstract] [paper] [arxiv] [webpage] [bibtex] [data] [code] [video] |
|
|
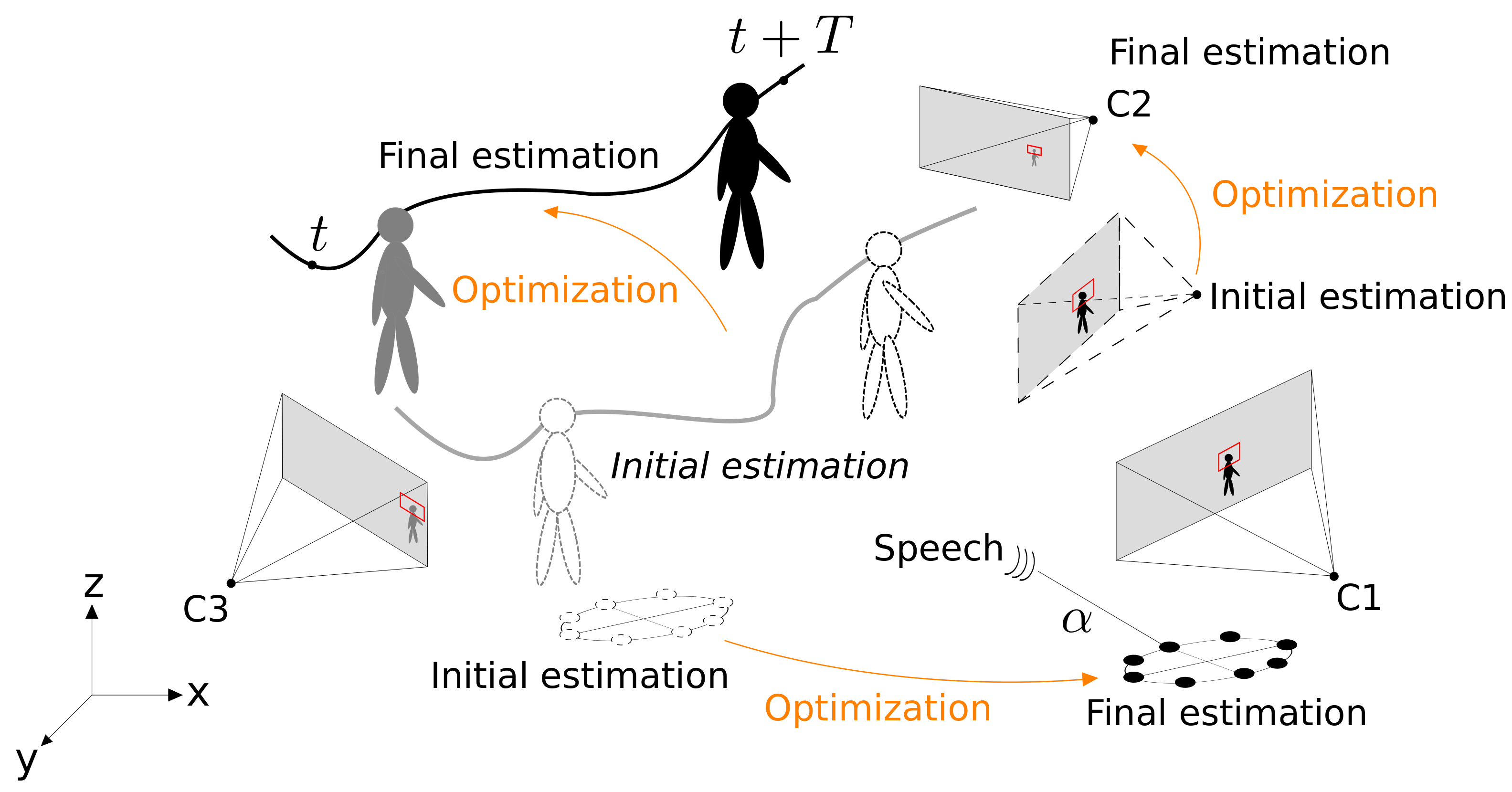
Accurate Target Annotation in 3D from Multimodal Streams O. Lanz, A. Brutti, A. Xompero, X. Qian, M. Omologo, and A. Cavallaro International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton (UK), May, 12-17, 2019 [abstract] [paper] [preprint] [bibtex] [CAV3D] |
|
|
MORB: a multi-scale binary descriptor A. Xompero, O. Lanz, and A. Cavallaro IEEE International Conference on Image Processing (ICIP), Athens (Greece), October, 7-10, 2018 [abstract] [paper] [preprint] [bibtex] [poster] [code] |
|
|
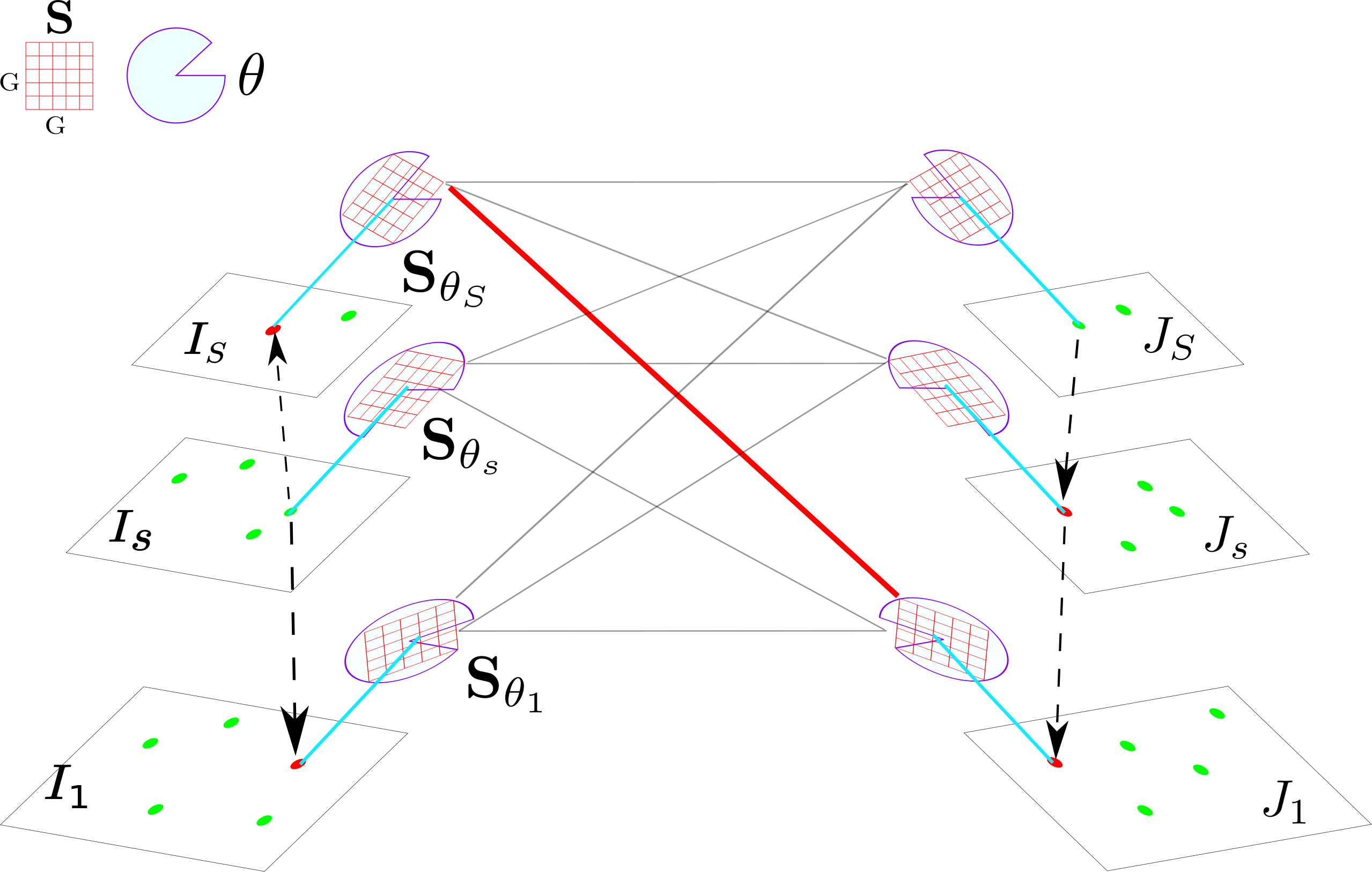
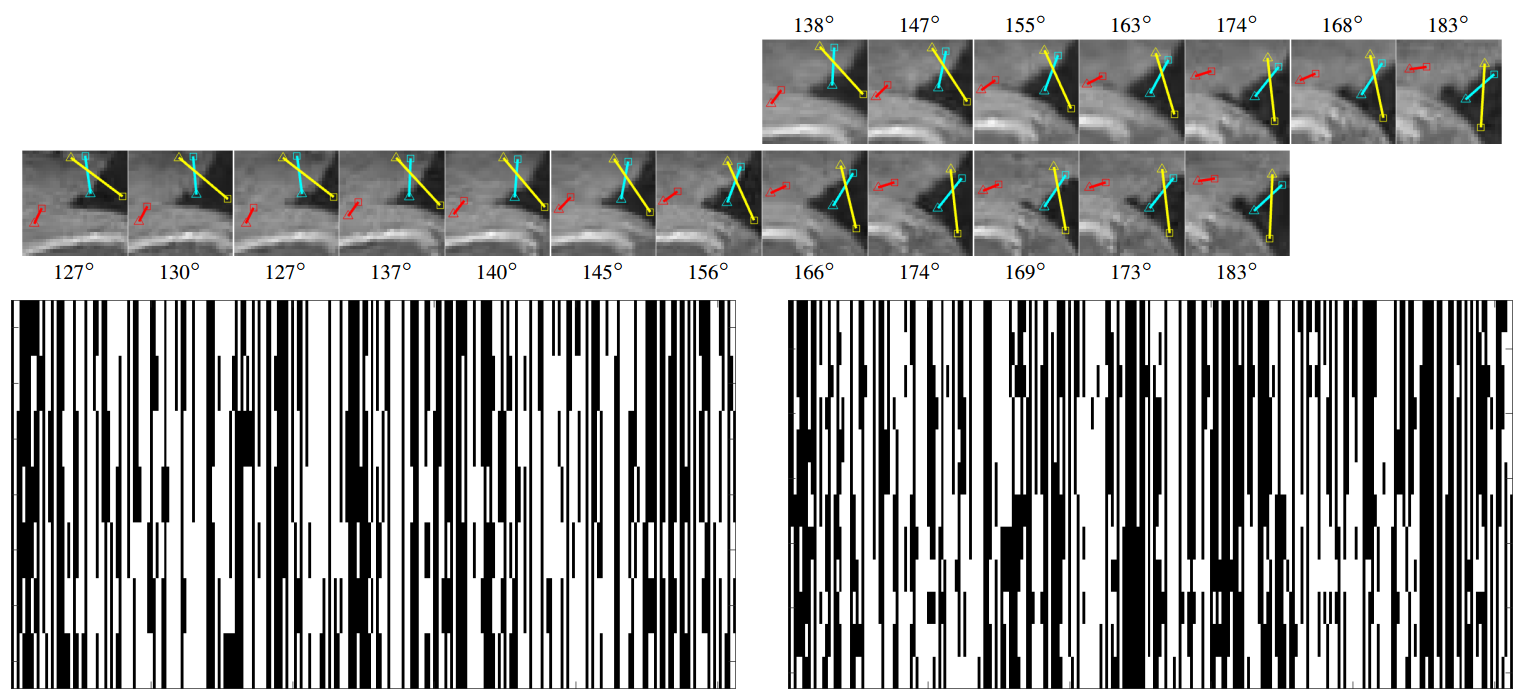
Multi-camera Matching of Spatio-Temporal Binary Features A. Xompero, O. Lanz, and A. Cavallaro International Conference on Information Fusion (FUSION), Cambridge (United Kingdom), July, 10-13, 2018 [abstract] [paper] [preprint] [bibtex] [slides] |
|

|
3D Mouth Tracking from a Compact Microphone Array Co-located with a Camera X. Qian, A. Xompero, A. Brutti, O. Lanz, M. Omologo, and A. Cavallaro IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary (Canada), April, 15-20, 2018 [abstract] [paper] [preprint] [bibtex] |
Workshops
Peer-reviewed workshop papers published in the corresponding conference workshop proceedings.
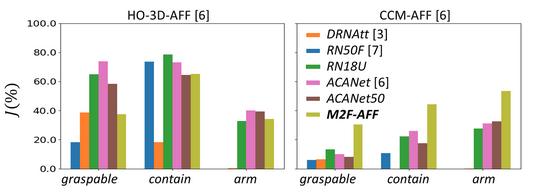 |
Segmenting Object Affordances: Reproducibility and Sensitivity to Scale T. Apicella, A. Xompero, P. Gastaldo, A. Cavallaro Twelth International Workshop on Assistive Computer Vision and Robotics (ACVR) European Conference on Computer Vision (ECCV), Milan (Italy), 29 September 2024. [abstract] [arxiv] [bibtex] [webpage] [poster] [code] [trained models] [eval-toolkit] | |
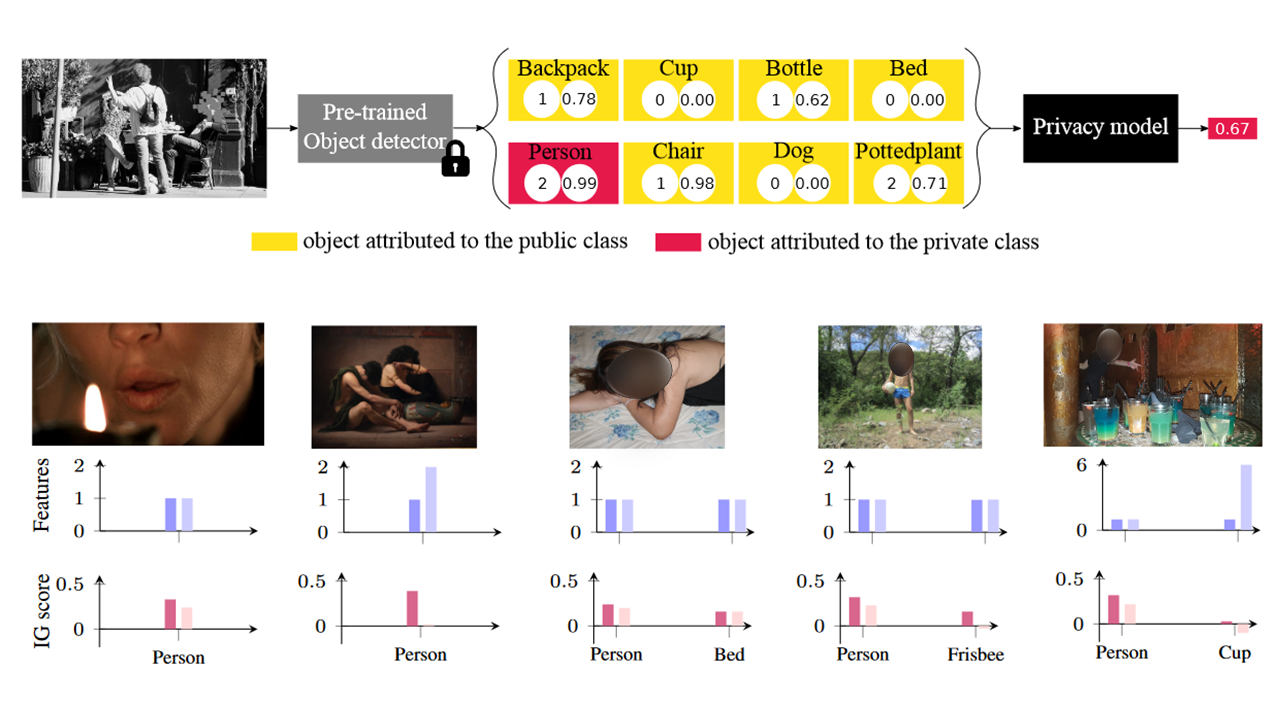 |
Explaining models relating objects and privacy A. Xompero, M. Bontonou, J. Arbona, E. Benetos, A. Cavallaro The 3rd Explainable AI for Computer Vision (XAI4CV) Workshop IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), Seattle (US), 18 June 2024. [abstract] [paper] [supp] [arxiv] [bibtex] [open access] [poster] [video] [code] [webpage] [XAI4CV] |
|
 |
Affordance segmentation of hand-occluded containers from exocentric images T. Apicella, A. Xompero, E. Ragusa, R. Berta, A. Cavallaro, P. Gastaldo Eleventh International Workshop on Assistive Computer Vision and Robotics (ACVR) International Conference on Computer Vision (ICCV), Paris (France), 2 October 2023. [abstract] [paper] [arxiv] [bibtex] [webpage] [CHOC-AFF data] [code] [trained model] |
|
 |
Cross-Camera View-Overlap Recognition A. Xompero, A. Cavallaro International Workshop on Smart Distributed Cameras (IWDSC) at European Conference on Computer Vision (ECCV), October 2022. [abstract] [paper] [arxiv] [bibtex] [webpage] [data] [code] [video] |
Pre-prints
 
|
Visual Affordances: Enabling robots to understand object functionality T. Apicella, A. Xompero, A. Cavallaro Under review, May 2025 [abstract] [arxiv] [bibtex] [webpage] [repo] |
|
 |
A Mixed-Reality Dataset for Category-level 6D Pose and Size Estimation of Hand-occluded Containers X. Weber, A. Xompero, A. Cavallaro [abstract] [arxiv] [bibtex] [webpage] [data] |
Thesis
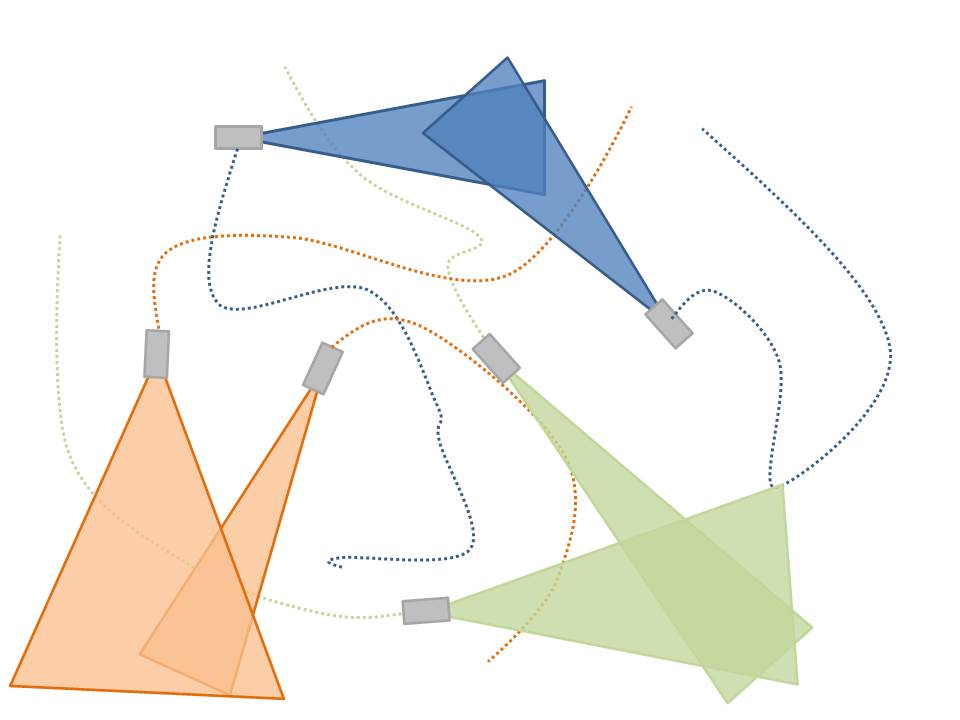
Local features for view matching across independently moving cameras
Alessio Xompero, PhD Thesis, Queen Mary University of London, United Kingdom, September 2020
Supervisors:
Prof. Andrea Cavallaro, Queen Mary University of London, United Kingdom
Dr. Oswald Lanz, Fondazione Bruno Kessler, Italy
Examiners:
Dr. Stefan Leutenegger, Imperial College London, United Kingdom
Dr. Jean-Yves Guillemaut, University of Surrey, United Kingdom
[pdf]
Alessio Xompero, PhD Thesis, Queen Mary University of London, United Kingdom, September 2020
Supervisors:
Prof. Andrea Cavallaro, Queen Mary University of London, United Kingdom
Dr. Oswald Lanz, Fondazione Bruno Kessler, Italy
Examiners:
Dr. Stefan Leutenegger, Imperial College London, United Kingdom
Dr. Jean-Yves Guillemaut, University of Surrey, United Kingdom
[pdf]

|
ViProT: A Visual Probabilistic Model for Moving Interest Points Clusters Tracking Alessio Xompero, Master's thesis, University of Trento, Italy, March 2015 Advisors: Dr. Nicola Conci, University of Trento, Italy Dr. Radu Patrice Horaud, INRIA Grenoble Rhône-Alpes, France Dr. Xavier Alameda-Pineda (Co-advisor), INRIA Grenoble Rhône-Alpes, France Dr. Sileye Ba (Co-advisor), INRIA Grenoble Rhône-Alpes, France [pdf] |