This page presents my research publications covering topics in computer vision, audio-visual signal processing, and robotics. My research interests include multi-view matching, feature descriptors, object tracking, human-robot interaction, visual privacy, and robotic affordances. The publications are organized by category and can be filtered by type and year.
Publications
Filter by Category:
Filter by Year:
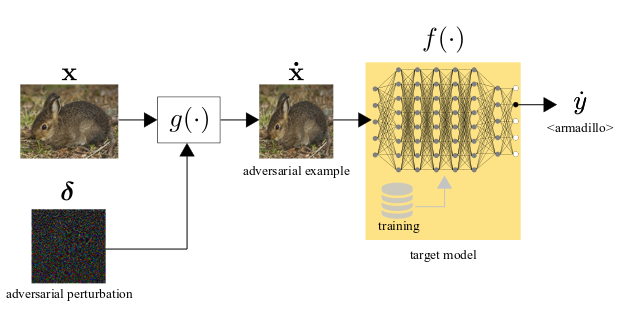
Chapter 15 - Visual adversarial attacks and defenses
In Advanced Methods And Deep Learning In Computer Vision, Editors: E. R. Davies, Matthew Turk, 1st Edition, Elsevier, pages 511-543, November 2022
Visual adversarial examples are images and videos purposefully perturbed to mislead machine learning models. This chapter presents an overview of methods that craft adversarial perturbations to generate visual adversarial examples for image classification, object detection, motion estimation and video recognition tasks. We define the key properties of an adversarial attack and the types of perturbations that an attack generates. We then analyze the main design choices for methods that craft adversarial attacks for images and videos, and discuss the knowledge they use of the target model. Finally, we review defense mechanisms that increase the robustness of machine learning models to adversarial attacks or detect manipulated input data.
@incollection{Oh2022VisualAdversarial,
title = {Chapter 15 - Visual adversarial attacks and defenses},
author = {Changjae Oh and Alessio Xompero and Andrea Cavallaro},
booktitle = {Advanced Methods and Deep Learning in Computer Vision},
editor = {E.R. Davies and Matthew A. Turk},
series = {Computer Vision and Pattern Recognition},
publisher = {Academic Press},
pages = {511-543},
year = {2022},
}
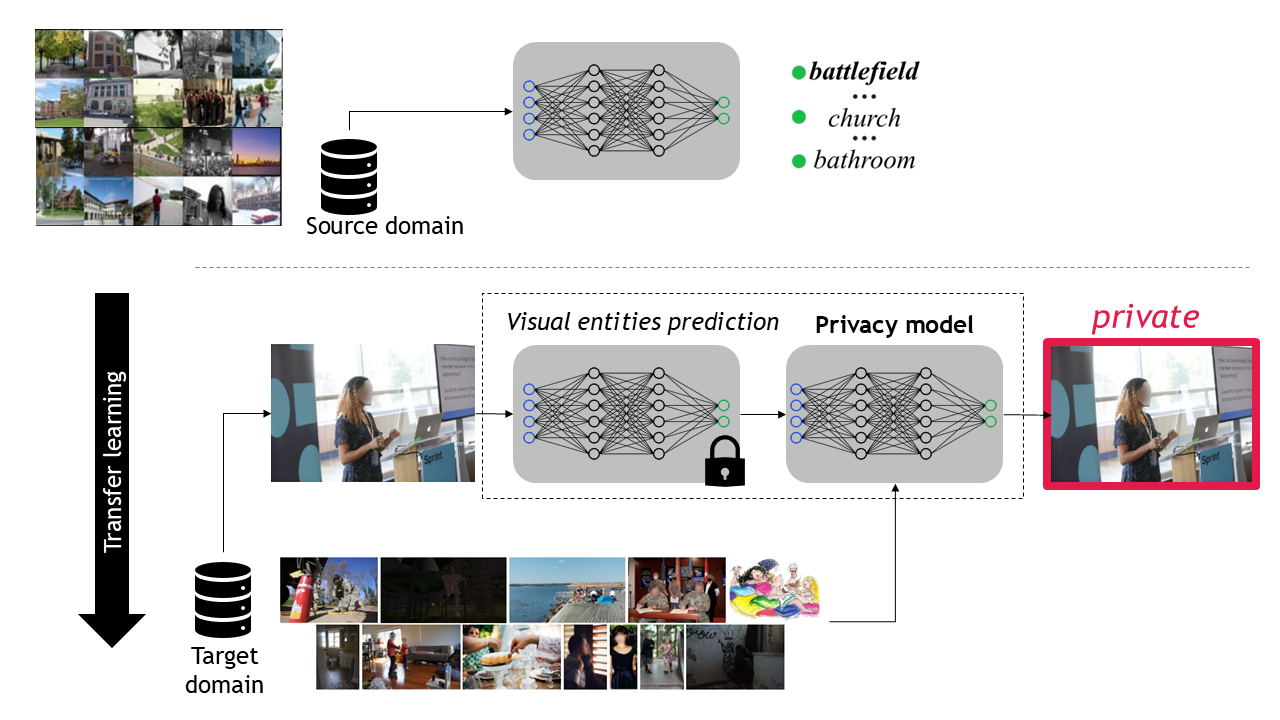
Learning Privacy from Visual Entities
Proceedings on Privacy Enhancing Technologies (PoPETs), vol. 2025, n. 3, pp. 1-21, March 2025
Subjective interpretation and content diversity make predicting whether an image is private or public a challenging task. Graph neural networks combined with convolutional neural networks (CNNs), which consist of 14,000 to 500 millions parameters, generate features for visual entities (e.g., scene and object types) and identify the entities that contribute to the decision. In this paper, we show that using a simpler combination of transfer learning and a CNN to relate privacy with scene types optimises only 732 parameters while achieving comparable performance to that of graph-based methods. On the contrary, end-to-end training of graph-based methods can mask the contribution of individual components to the classification performance. Furthermore, we show that a high-dimensional feature vector, extracted with CNNs for each visual entity, is unnecessary and complexifies the model. The graph component has also negligible impact on performance, which is driven by fine-tuning the CNN to optimise image features for privacy nodes.
@Article{Xompero2025PoPETs,
title = {Learning Privacy from Visual Entities},
author = {Xompero, A. and Cavallaro, A.},
journal = {Proceedings on Privacy Enhancing Technologies},
volume = {2025},
number = {3},
pages={1--21},
month = {Mar},
year = {2025},
}
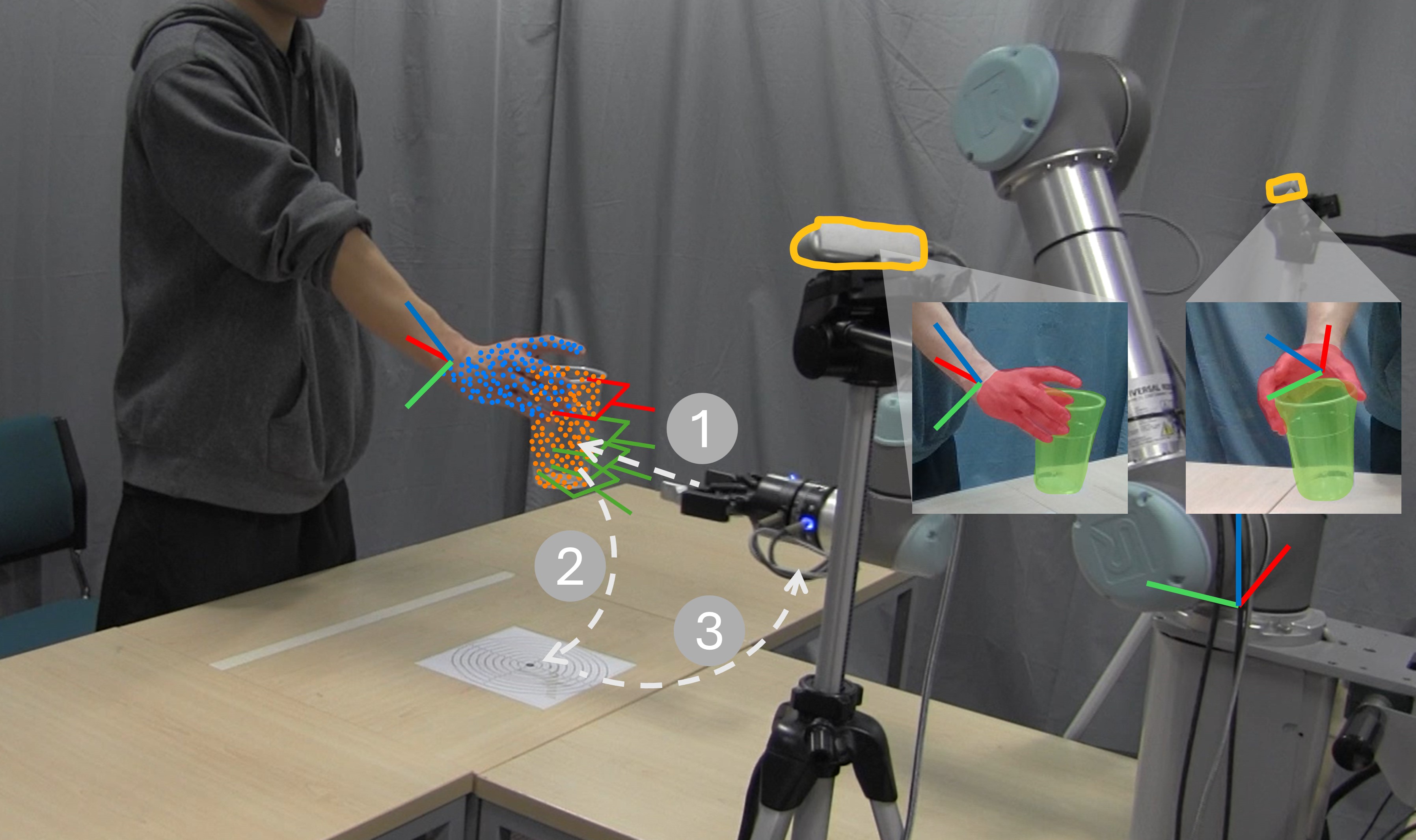
Stereo Hand-Object Reconstruction for Human-to-Robot Handover
IEEE Robotics and Automation Letters, Vol.10, n.6, June 2025. To be presented at IEEE/RSJ Int. Conf. Intell. Robots and Systems (IROS), Hangzhou, China, 19-25 October 2025
Jointly estimating hand and object shape facilitates the grasping task in human-to-robot handovers. Relying on hand-crafted prior knowledge about the geometric structure of the object fails when generalising to unseen objects, and depth sensors fail to detect transparent objects such as drinking glasses. In this work, we propose a method for hand-object reconstruction that combines single-view reconstructions probabilistically to form a coherent stereo reconstruction. We learn 3D shape priors from a large synthetic hand-object dataset, and use RGB inputs to better capture transparent objects. We show that our method reduces the object Chamfer distance compared to existing RGB based hand-object reconstruction methods on single view and stereo settings. We process the reconstructed hand-object shape with a projection-based outlier removal step and use the output to guide a human-to-robot handover pipeline with wide-baseline stereo RGB cameras. Our hand-object reconstruction enables a robot to successfully receive a diverse range of household objects from the human.
@article{Pang2025RAL,
title = {Stereo Hand-Object Reconstruction for Human-to-Robot Handover},
author = {Pang, Y. L. and Xompero, A. and Oh, C. and Cavallaro, A.},
journal={IEEE Robotics and Automation Letters},
year={2025},
volume={10},
number={6},
pages={5761--5768},
doi={10.1109/LRA.2025.3562790}
}
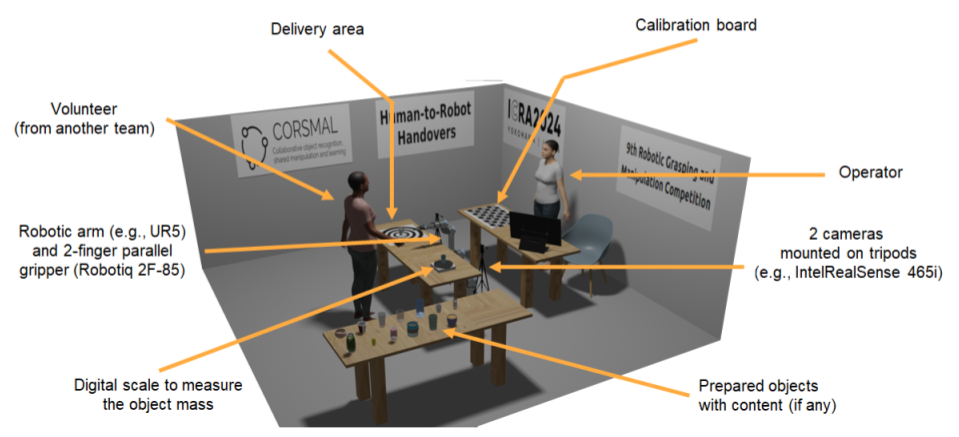
Robotic Grasping and Manipulation Competition at the 2024 IEEE/RAS International Conference on Robotics and Automation
IEEE Robotics & Automation Magazine, Competitions, vol. 31, n. 4, pp. 174-185, December 2024
The Ninth Robotic Grasping and Manipulation Competition (RGMC) took place in Yokohama, Japan, during the 2024 IEEE/RAS International Conference on Robotics and Automation (ICRA). The series of RGMC events started in 2016 at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) with strong support from the conference's organization committee, and since then they have been held each year at ICRA or IROS. Across the editions, RGMC engaged the community in solving the open challenges associated with various robotic grasping and manipulation tasks for manufacturing, service robots, and logistics, and in advancing research and technology towards more realistic scenarios that can be encountered in daily activities at home or in warehouses.
@Article{Sun2024RAM,
title = {Robotic Grasping and Manipulation Competition at the 2024 IEEE/RAS International Conference on Robotics and Automation},
author = {Sun, Y., and Calli, B. and Kimble, K. and wyffels, F. and De Gusseme, V. and Hang, K. and D'Avella, S. and Xompero, A. and Cavallaro, A. and Roa, M. A. and Avendano, J. and Mavrommati, A.},
journal = {IEEE Robotics and Automation Magazine},
volume = {31},
number = {4},
pages={174--185},
month = {Dec},
year = {2024},
}
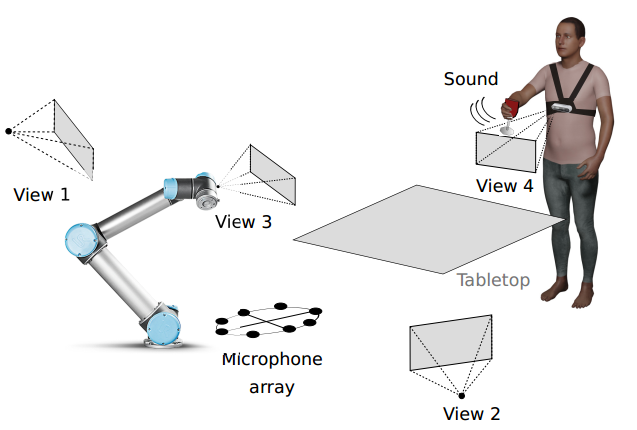
The CORSMAL Benchmark for the Prediction of the Properties of Containers
IEEE Access, vol. 10, 2022
The contactless estimation of the weight of a container and the amount of its content manipulated by a person are key pre-requisites for safe human-to-robot handovers. However, opaqueness and transparencies of the container and the content, and variability of materials, shapes, and sizes, make this problem challenging. In this paper, we present a range of methods and an open framework to benchmark acoustic and visual perception for the estimation of the capacity of a container, and the type, mass, and amount of its content.
@Article{Xompero2022Access,
title = {The CORSMAL Benchmark for the Prediction of the Properties of Containers},
author = {Xompero, A. and Donaher, S. and Iashin, V. and Palermo, F. and Solak, G. and Coppola, C. and Ishikawa, R. and Nagao, Y. and Hachiuma, R. and Liu, Q. and Feng, F. and Lan, C. and Chan, R. H. M. and Christmann, G. and Song, J. and Neeharika, G. and Reddy, C. K. T. and Jain, D. and Rehman, B. U. and Cavallaro, A.},
journal = {IEEE Access},
volume = {10},
pages={41388--41402},
month = {Apr},
year = {2022},
}
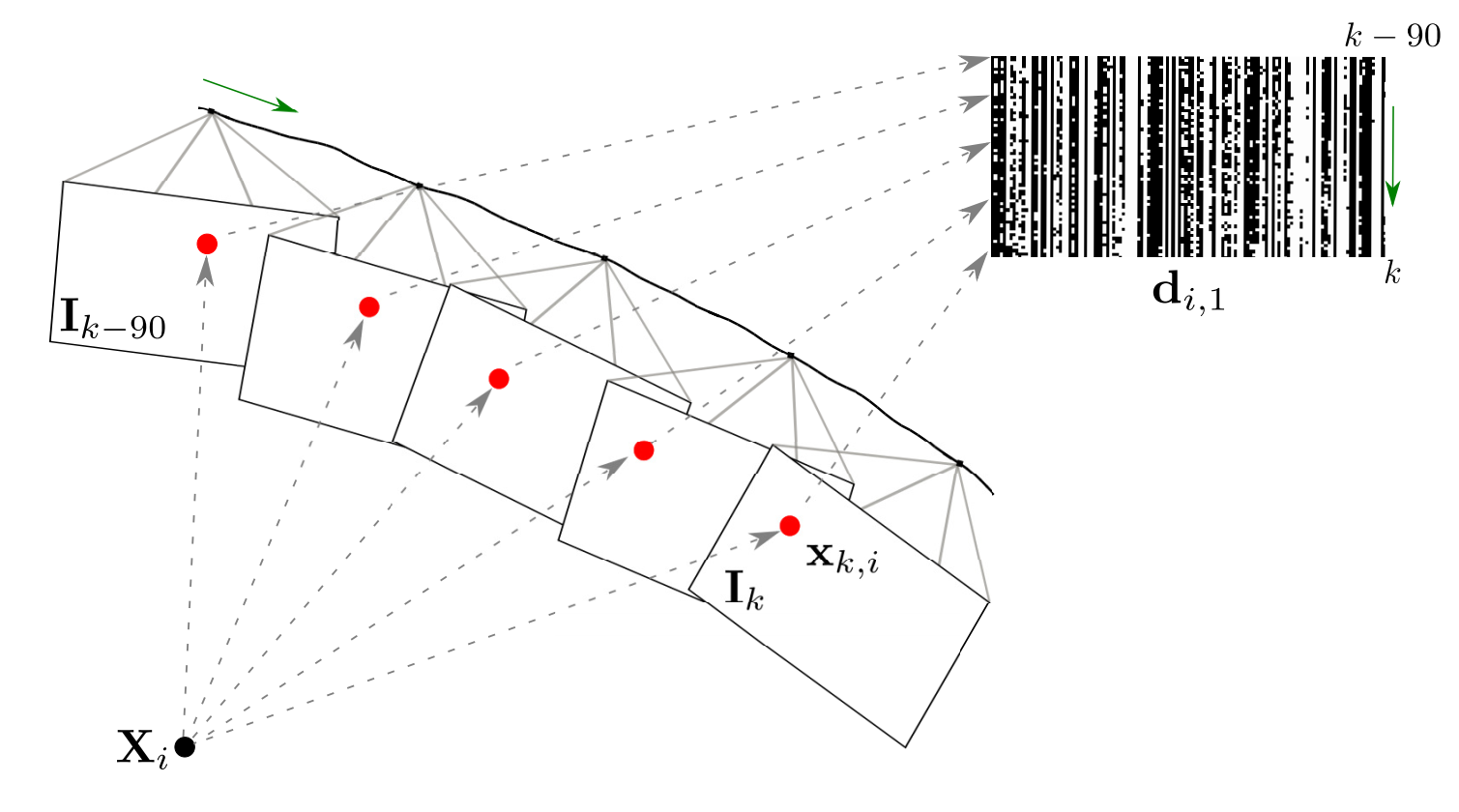
A spatio-temporal multi-scale binary descriptor
IEEE Transactions on Image Processing, vol. 29, no. 1, pp. 4362-4375, Dec. 2020
Binary descriptors are widely used for multi-view matching and robotic navigation. However, their matching performance decreases considerably under severe scale and viewpoint changes in non-planar scenes. To overcome this problem, we propose to encode the varying appearance of selected 3D scene points tracked by a moving camera with compact spatio-temporal descriptors. To this end, we first track interest points and capture their temporal variations at multiple scales. Then, we validate feature tracks through 3D reconstruction and compress the temporal sequence of descriptors by encoding the most frequent and stable binary values. Finally, we determine multi-scale correspondences across views with a matching strategy that handles severe scale differences.
@Article{Xompero2020TIP_MST,
title={A spatio-temporal multi-scale binary descriptor},
author={Alessio Xompero and Oswald Lanz and Andrea Cavallaro},
journal={IEEE Transactions on Image Processing},
volume={29},
number={1},
pages={4362--4375},
month={Dec},
year={2020},
issn={1057-7149},
doi={10.1109/TIP.2020.2965277}
}

Benchmark for Human-to-Robot Handovers of Unseen Containers with Unknown Filling
IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1642-1649, Apr. 2020
The real-time estimation through vision of the physical properties of objects manipulated by humans is important to inform the control of robots for performing accurate and safe grasps of objects handed over by humans. However, estimating the 3D pose and dimensions of previously unseen objects using only RGB cameras is challenging due to illumination variations, reflective surfaces, transparencies, and occlusions caused both by the human and the robot. In this paper we present a benchmark for dynamic human-to-robot handovers that do not rely on a motion capture system, markers, or prior knowledge of specific objects.
@Article{SanchezMatilla2020RAL_Benchmark,
title={Benchmark for Human-to-Robot Handovers of Unseen Containers with Unknown Filling},
author={Ricardo Sanchez-Matilla, Konstantinos Chatzilygeroudis, Apostolos Modas, Nuno Ferreira Duarte, Alessio Xompero, Pascal Frossard, Aude Billard, and Andrea Cavallaro},
journal={IEEE Robotics and Automation Letters},
volume={5},
number={2},
pages={1642--1649},
month={Apr},
year={2020},
issn={2377-3766},
doi={10.1109/LRA.2020.2969200}
}

An On-line Variational Bayesian Model for Multi-Person Tracking from Cluttered Scenes
Computer Vision and Image Understanding, 2016
Object tracking is an ubiquitous problem that appears in many applications such as remote sensing, audio processing, computer vision, human-machine interfaces, human-robot interaction, etc. Although thoroughly investigated in computer vision, tracking a time-varying number of persons remains a challenging open problem. In this paper, we propose an on-line variational Bayesian model for multi-person tracking from cluttered visual observations provided by person detectors.
@article{Ba2016cviu,
title = {An On-line Variational Bayesian Model for Multi-Person Tracking from Cluttered Scenes},
author = {Ba, S. and Alameda-Pineda, X. and Xompero, A. and Horaud, R.},
journal = {Computer Vision and Image Understanding},
volume={153},
pages={64--76},
month = apr,
year = {2016},
}

Audio-Visual Object Classification for Human-Robot Collaboration
IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Singapore and Virtual, 22-27 May 2022
Human-robot collaboration requires the contactless estimation of the physical properties of containers manipulated by a person, for example while pouring content in a cup or moving a food box. Acoustic and visual signals can be used to estimate the physical properties of such objects, which may vary substantially in shape, material and size, and also be occluded by the hands of the person. To facilitate comparisons and stimulate progress in solving this problem, we present the CORSMAL challenge and a dataset to assess the performance of the algorithms through a set of well-defined performance scores.
@InProceedings{Xompero2022ICASSP,
title = {Audio-Visual Object Classification for Human-Robot Collaboration},
author = {Xompero, A. and Pang, Y. L. and Patten, T. and Prabhakar, A. and Calli, B. and Cavallaro, A.},
booktitle = {IEEE International Conference on Acoustic, Speech and Signal Processing},
address={Singapore},
month="22--27~" # MAY,
year = {2022},
}

Towards safe human-to-robot handovers of unknown containers
IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Virtual, 8-12 Aug 2021
Safe human-to-robot handovers of unknown containers require accurate estimation of the human and object properties, such as hand pose, object shape, trajectory, and weight. However, accurate estimation requires the use of expensive equipment, such as motion capture systems, markers, and 3D object models. Moreover, developing and testing on real hardware can be dangerous for the human and object. We propose a real-to-simulation framework to conduct safe human-to-robot handovers with visual estimations of the physical properties of unknown cups or drinking glasses and of the human hands from videos of a person manipulating the object.
@Article{Pang2021ROMAN,
title = {Towards safe human-to-robot handovers of unknown containers},
author = {Yik Lang Pang and Alessio Xompero and Changjae Oh and Andrea Cavallaro},
booktitle = {IEEE International Conference on Robot and Human Interactive Communication},
address = {Virtual},
month = "8-12~" # aug,
year = {2021},
}

Improving filling level classification with adversarial training
IEEE International Conference on Image Processing (ICIP), Anchorage, Alaska, USA, 19-22 Sep 2021
We investigate the problem of classifying -- from a single image -- the level of content in a cup or a drinking glass. This problem is made challenging by several ambiguities caused by transparencies, shape variations and partial occlusions, and by the availability of only small training datasets. In this paper, we tackle this problem with an appropriate strategy for transfer learning. Specifically, we use adversarial training in a generic source dataset and then refine the training with a task-specific dataset.
@Article{Modas2021ICIP,
title = {Improving filling level classification with adversarial training},
author = {Apostolos Modas and Alessio Xompero and Ricardo Sanchez-Matilla and Pascal Frossard and Andrea Cavallaro},
booktitle = {IEEE International Conference on Image Processing},
address = {Anchorage, Alaska, USA},
month = "19-22~" # sep,
year = {2021},
}

Audio classification of the content of food containers and drinking glasses
European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23-27 August 2021
Food containers, drinking glasses and cups handled by a person generate sounds that vary with the type and amount of their content. In this paper, we propose a new model for sound-based classification of the type and amount of content in a container. The proposed model is based on the decomposition of the problem into two steps, namely action recognition and content classification. We consider the scenario of the recent CORSMAL Containers Manipulation dataset and consider two actions (shaking and pouring), and seven material and filling level combinations.
@Article{Donhaer2021EUSIPCO,
title={Audio classification of the content of food containers and drinking glasses},
author={Santiago Donhaer and Alessio Xompero and Andrea Cavallaro},
booktitle={European Signal Processing Conference},
address={Dublin, Ireland},
month = "23-27~" # aug,
year={2021},
}
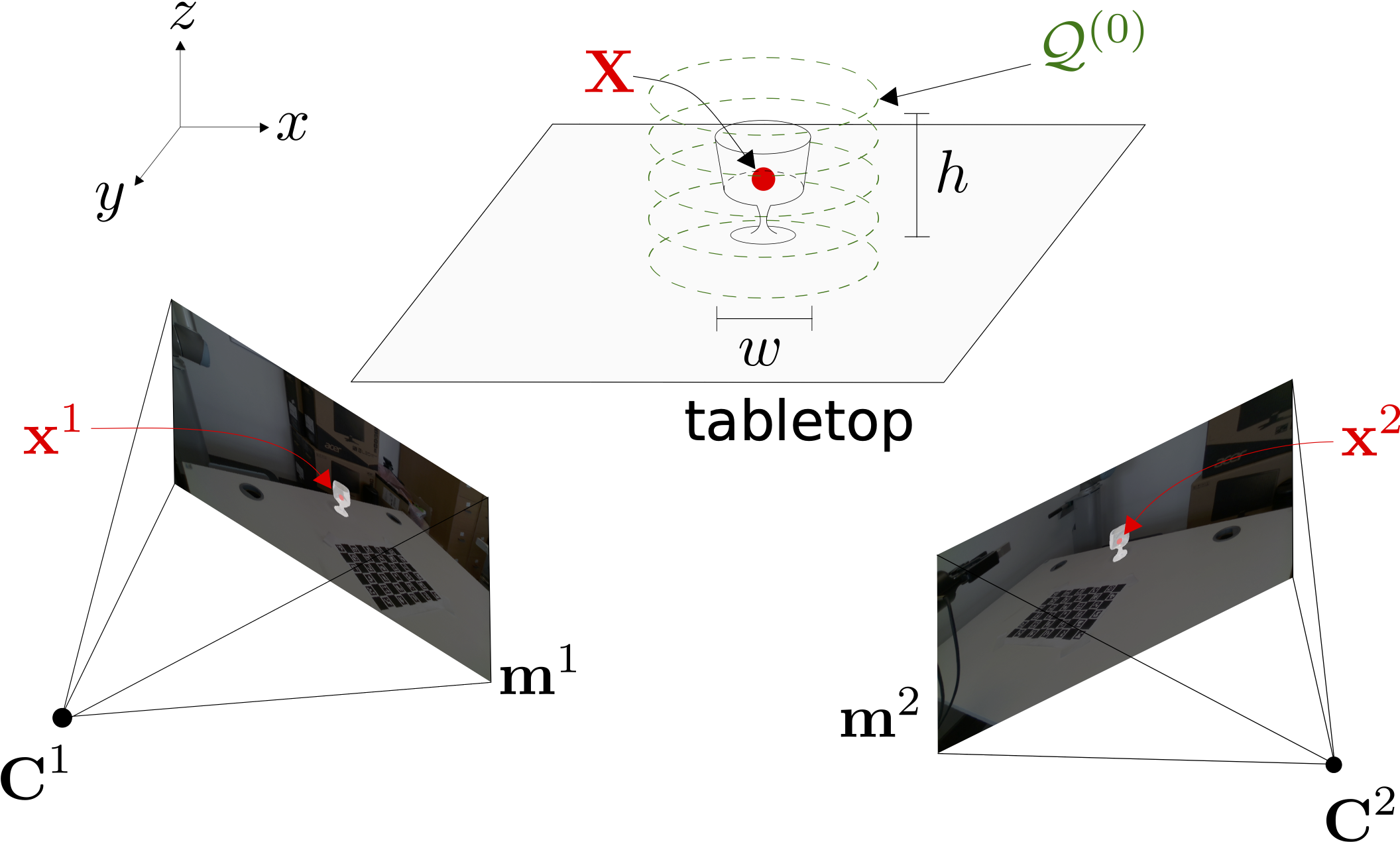
Multi-view shape estimation of transparent containers
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4-8 May 2020
The 3D localisation of an object and the estimation of its properties, such as shape and dimensions, are challenging under varying degrees of transparency and lighting conditions. In this paper, we propose a method for jointly localising container-like objects and estimating their dimensions using two wide-baseline, calibrated RGB cameras. Under the assumption of circular symmetry along the vertical axis, we estimate the dimensions of an object with a generative 3D sampling model of sparse circumferences, iterative shape fitting and image re-projection to verify the sampling hypotheses in each camera using semantic segmentation masks.
@InProceedings{Xompero2020ICASSP_LoDE,
title={Multi-view shape estimation of transparent containers},
author={Alessio Xompero and Ricardo Sanchez-Matilla and Apostolos Modas and Pascal Frossard and Andrea Cavallaro},
booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing},
address = {Barcelona, Spain},
month = "4-8~" # may,
year = {2020}
}
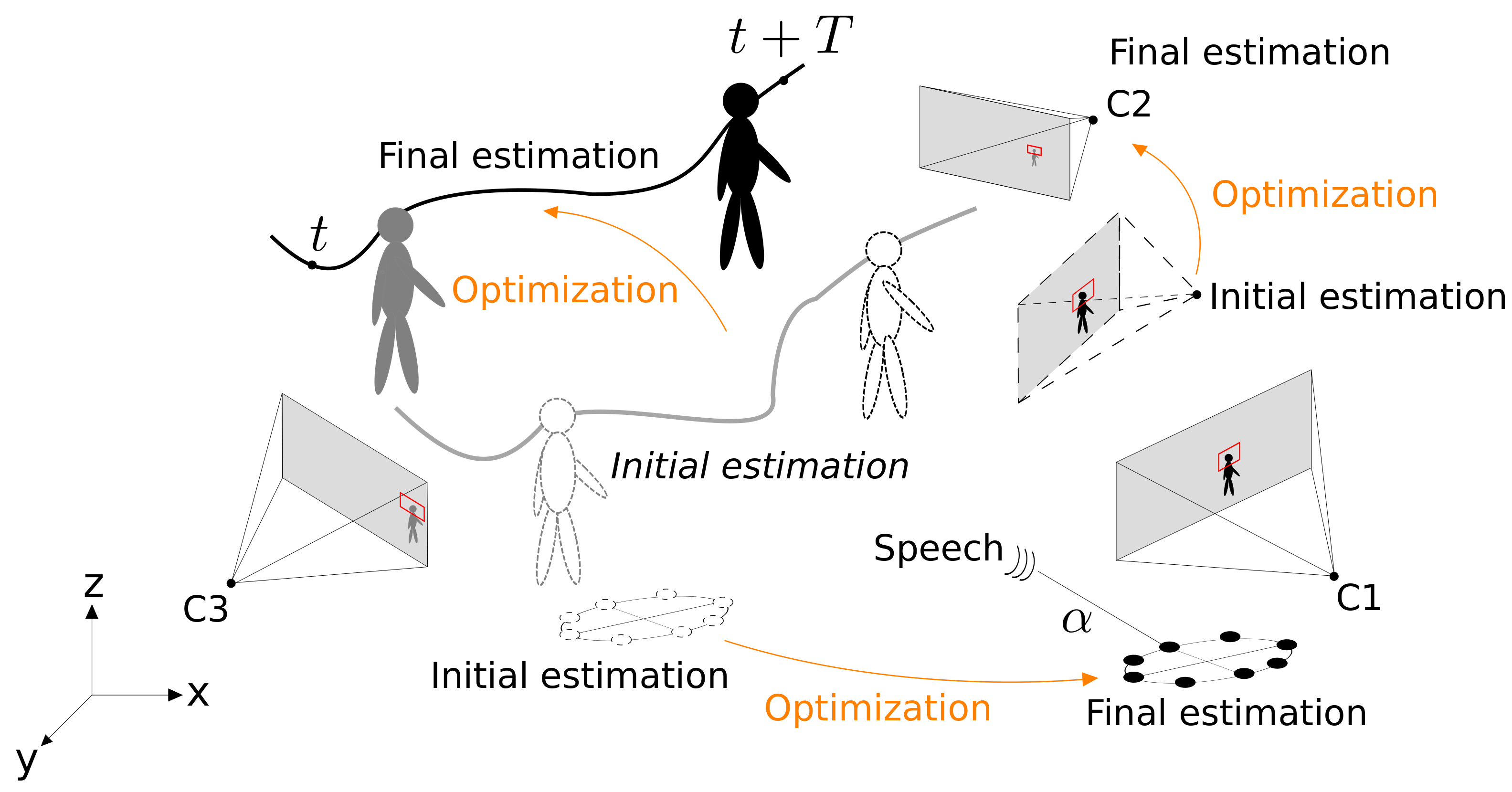
Accurate Target Annotation in 3D from Multimodal Streams
International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton (UK), May, 12-17, 2019
Accurate annotation is fundamental to quantify the performance of multi-sensor and multi-modal object detectors and trackers. However, invasive or expensive instrumentation is needed to automatically generate these annotations. To mitigate this problem, we present a multi-modal approach that leverages annotations from reference streams (e.g. individual camera views) and measurements from unannotated additional streams (e.g. audio) to infer 3D trajectories through an optimization. The core of our approach is a multi-modal extension of Bundle Adjustment with a cross-modal correspondence detection that selectively uses measurements in the optimization.
@INPROCEEDINGS{Lanz2019ICASSP,
title = {Accurate target annotation in 3D from multimodal streams},
author = {Lanz, Oswald and Brutti, Alessio and Xompero, Alessio and Qian, Xinyuan and Omologo, Maurizio and Cavallaro, Andrea},
booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing},
address = {Brighton, UK},
month = "12--17~" # may,
year = {2019}
}
MORB: a multi-scale binary descriptor
IEEE International Conference on Image Processing (ICIP), Athens (Greece), October, 7-10, 2018
Local image features play an important role in matching images under different geometric and photometric transformations. However, as the scale difference across views increases, the matching performance may considerably decrease. To address this problem we propose MORB, a multi-scale binary descriptor that is based on ORB and that improves the accuracy of feature matching under scale changes. MORB describes an image patch at different scales using an oriented sampling pattern of intensity comparisons in a predefined set of pixel pairs.
@INPROCEEDINGS{Xompero2018ICIP_MORB,
title = {{MORB: a multi-scale binary descriptor}},
author = {Xompero, Alessio and Lanz, Oswald and Cavallaro, Andrea},
booktitle = {IEEE International Conference on Image Processing},
address = {Athens, Greece},
month = "7--10~" # oct,
year = {2018}
}
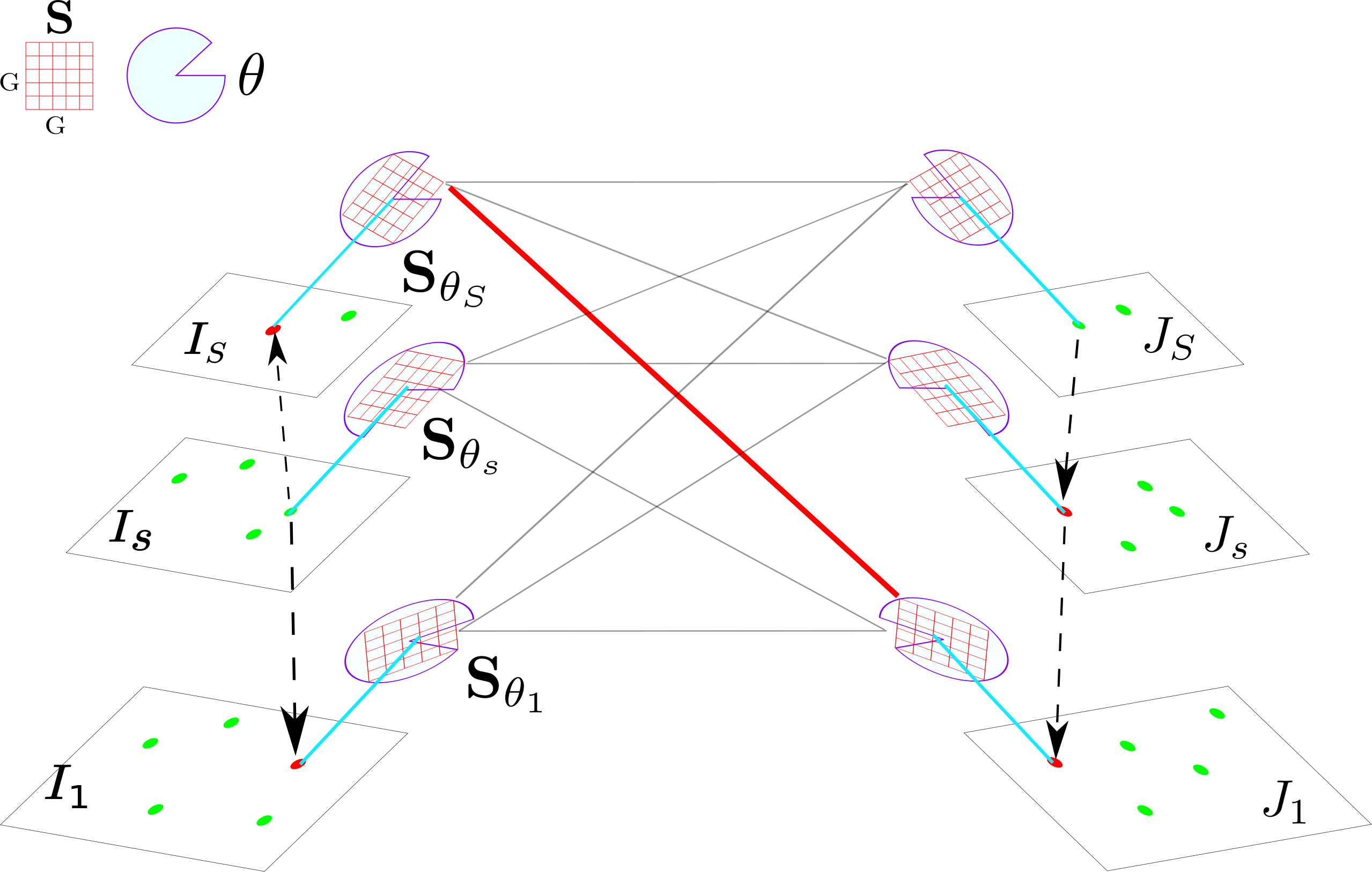
Multi-camera Matching of Spatio-Temporal Binary Features
International Conference on Information Fusion (FUSION), Cambridge (United Kingdom), July, 10-13, 2018
Local image features are generally robust to different geometric and photometric transformations on planar surfaces or under narrow baseline views. However, the matching performance decreases considerably across cameras with unknown poses separated by a wide baseline. To address this problem, we accumulate temporal information within each view by tracking local binary features, which encode intensity comparisons of pixel pairs in an image patch.
@INPROCEEDINGS{Xompero2018FUSION,
title = {{Multi-camera Matching of Spatio-Temporal Binary Features}},
author = {Xompero, Alessio and Lanz, Oswald and Cavallaro, Andrea},
booktitle = {International Conference on Information Fusion},
address = {Cambridge, UK},
month = "10--13~" # jul,
year = {2018}
}

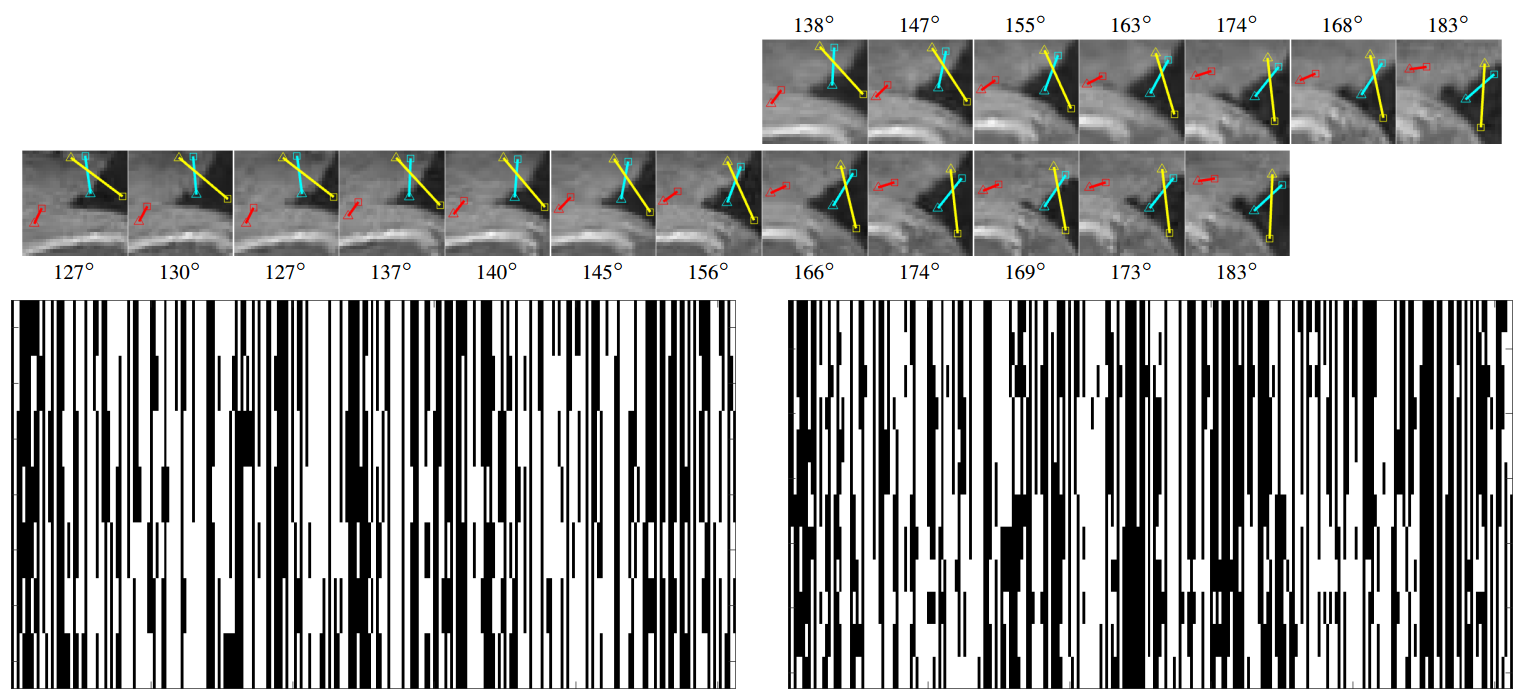
3D Mouth Tracking from a Compact Microphone Array Co-located with a Camera
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary (Canada), April, 15-20, 2018
We address the 3D audio-visual mouth tracking problem when using a compact platform with co-located audio-visual sensors, without a depth camera. In particular, we propose a multi-modal particle filter that combines a face detector and 3D hypothesis mapping to the image plane. The audio likelihood computation is assisted by video, which relies on a GCC-PHAT based acoustic map. By combining audio and video inputs, the proposed approach can cope with a reverberant and noisy environment, and can deal with situations when the person is occluded, outside the Field of View (FoV), or not facing the sensors.
@INPROCEEDINGS{Qian2018ICASSP,
title = {{3D Mouth Tracking from a Compact Microphone Array Co-located with a Camera}},
author = {Qian, Xinyuan and Xompero, Alessio and Brutti, Alessio and Lanz, Oswald and Omologo, Maurizio and Cavallaro, Andrea},
booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing},
address = {Calgary, Canada},
month = "15--20~" # apr,
year = {2018}
}
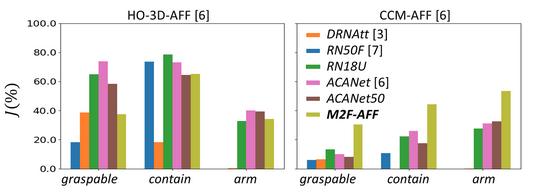
Segmenting Object Affordances: Reproducibility and Sensitivity to Scale
Twelth International Workshop on Assistive Computer Vision and Robotics (ACVR), European Conference on Computer Vision (ECCV), Milan (Italy), 29 September 2024
Visual affordance segmentation identifies image regions of an object an agent can interact with. Existing methods re-use and adapt learning-based architectures for semantic segmentation to the affordance segmentation task and evaluate on small-size datasets. However, experimental setups are often not reproducible, thus leading to unfair and inconsistent comparisons. In this work, we benchmark these methods under a reproducible setup on two single objects scenarios, tabletop without occlusions and hand-held containers, to facilitate future comparisons.
@InProceedings{Apicella2024ACVR_ECCVW,
title = {Segmenting Object Affordances: Reproducibility and Sensitivity to Scale},
author = {Apicella, T. and Xompero, A. and Gastaldo, P. and Cavallaro, A.},
booktitle = {Proceedings of the European Conference on Computer Vision Workshops},
note = {Twelfth International Workshop on Assistive Computer Vision and Robotics},
address={Milan, Italy},
month="29" # SEP,
year = {2024},
}
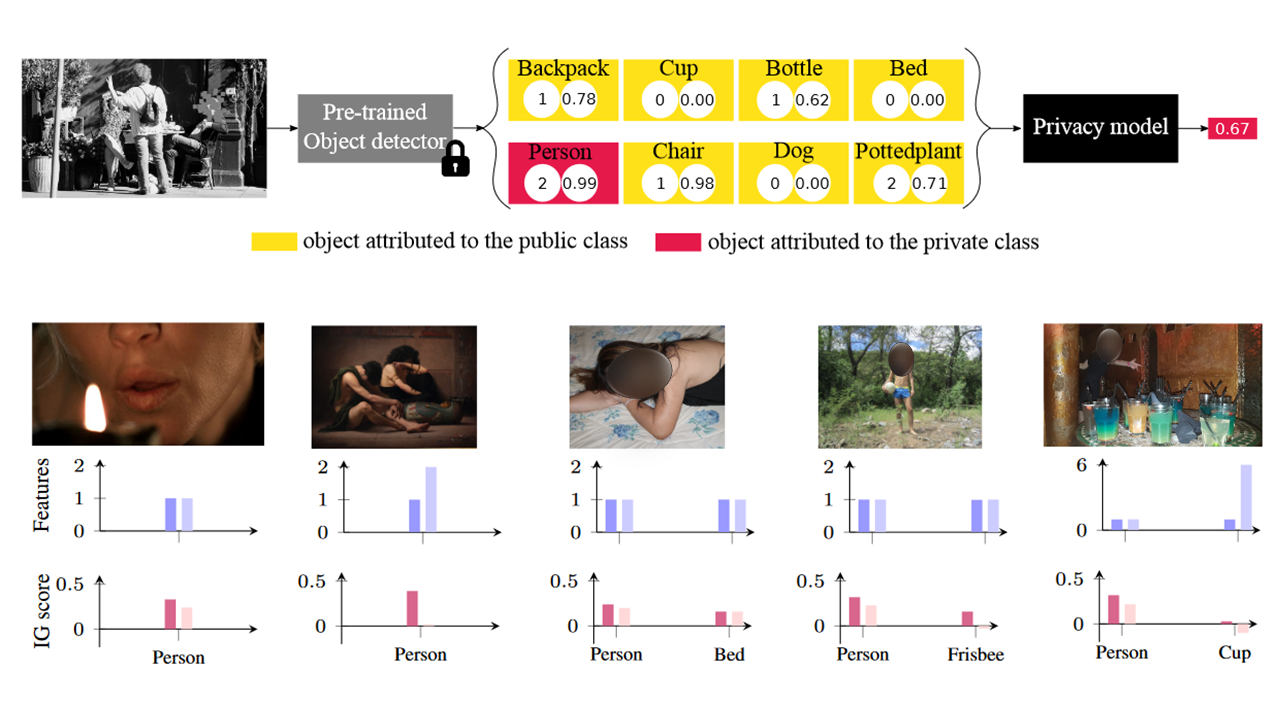
Explaining models relating objects and privacy
The 3rd Explainable AI for Computer Vision (XAI4CV) Workshop, IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), Seattle (US), 18 June 2024
Accurately predicting whether an image is private before sharing it online is difficult due to the vast variety of content and the subjective nature of privacy itself. In this paper, we evaluate privacy models that use objects extracted from an image to determine why the image is predicted as private. To explain the decision of these models, we use feature-attribution to identify and quantify which objects (and which of their features) are more relevant to privacy classification with respect to a reference input (i.e., no objects localised in an image) predicted as public. We show that the presence of the person category and its cardinality is the main factor for the privacy decision.
@Article{Xompero2024CPVRW_XAI4CV,
title = {Explaining models relating objects and privacy},
author={Xompero, A. and Bontonou, M. and Arbona, J. and Benetos, E. and Cavallaro, A.},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition Workshops},
note = {The 3rd Explainable AI for Computer Vision (XAI4CV) Workshop},
month="18" # JUN,
year = {2024},
}

Affordance segmentation of hand-occluded containers from exocentric images
Eleventh International Workshop on Assistive Computer Vision and Robotics (ACVR), International Conference on Computer Vision (ICCV), Paris (France), 2 October 2023
Visual affordance segmentation identifies the surfaces of an object an agent can interact with. Common challenges for the identification of affordances are the variety of the geometry and physical properties of these surfaces as well as occlusions. In this paper, we focus on occlusions of an object that is hand-held by a person manipulating it. To address this challenge, we propose an affordance segmentation model that uses auxiliary branches to process the object and hand regions separately.
@Article{Apicella2023ICCVW,
title = {Affordance segmentation of hand-occluded containers from exocentric images},
author={Apicella, T. and Xompero, A., and Ragusa, E. and Berta, R. and Cavallaro, A. and Gastaldo, P.},
booktitle = {Proceedings of the International Conference on Computer Vision Workshops},
note = {International Workshop on Assistive Computer Vision and Robotics},
month="2" # OCT,
year = {2023},
}

Cross-Camera View-Overlap Recognition
International Workshop on Smart Distributed Cameras (IWDSC) at European Conference on Computer Vision (ECCV), October 2022
We propose a decentralised view-overlap recognition framework that operates across freely moving cameras without the need of a reference 3D map. Each camera independently extracts, aggregates into a hierarchical structure, and shares feature-point descriptors over time. A view overlap is recognised by view-matching and geometric validation to discard wrongly matched views. The proposed framework is generic and can be used with different descriptors.
@Article{Xompero2022IWDSC,
title = {Cross-Camera View-Overlap Recognition},
author = {Xompero, A. and Cavallaro, A.},
booktitle = {Proceedings of the European Conference on Computer Vision Workshops},
note = {International Workshop on Distributed Smart Cameras},
month="24" # OCT,
year = {2022},
}
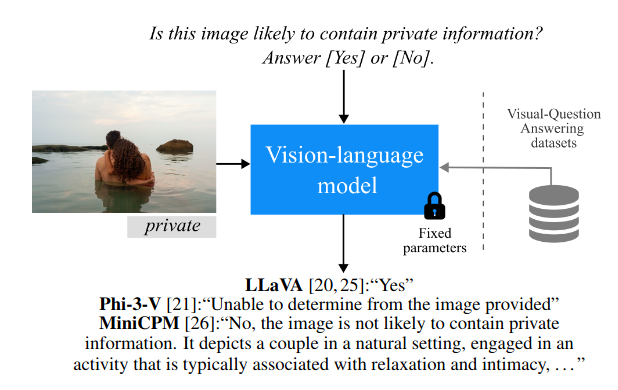
Zero-Shot Image Privacy Classification with Vision-Language Models
September 2025
While specialized learning-based models have historically dominated image privacy prediction, the current literature increasingly favours adopting large Vision-Language Models (VLMs) designed for generic tasks. This trend risks overlooking the performance ceiling set by purpose-built models due to a lack of systematic evaluation. To address this problem, we establish a zero-shot benchmark for image privacy classification, enabling a fair comparison. We evaluate the top-3 open-source VLMs, according to a privacy benchmark, using task-aligned prompts and we contrast their performance, efficiency, and robustness against established vision-only and multi-modal methods.
@misc{Baia2025_VLM_Privacy,
title = {Zero-Shot Image Privacy Classification with Vision-Language Models},
author = {Baia, A. E. and Xompero, A. and Cavallaro, A.},
year=2025
}

Visual Affordances: Enabling robots to understand object functionality
May 2025
Human-robot interaction for assistive technologies relies on the prediction of affordances, which are the potential actions a robot can perform on objects. Predicting object affordances from visual perception is formulated differently for tasks such as grasping detection, affordance classification, affordance segmentation, and hand-object interaction synthesis. In this work, we highlight the reproducibility issue in these redefinitions, making comparative benchmarks unfair and unreliable. To address this problem, we propose a unified formulation for visual affordance prediction, provide a comprehensive and systematic review of previous works highlighting strengths and limitations of methods and datasets, and analyse what challenges reproducibility.
@misc{Apicella2025,
title = {Visual Affordances: Enabling robots to understand object functionality},
author = {Apicella, T. and Xompero, A. and Cavallaro, A.},
year=2025
}

A Mixed-Reality Dataset for Category-level 6D Pose and Size Estimation of Hand-occluded Containers
arXiv, 2022
Estimating the 6D pose and size of household containers is challenging due to large intra-class variations in the object properties, such as shape, size, appearance, and transparency. The task is made more difficult when these objects are held and manipulated by a person due to varying degrees of hand occlusions caused by the type of grasps and by the viewpoint of the camera observing the person holding the object. In this paper, we present a mixed-reality dataset of hand-occluded containers for category-level 6D object pose and size estimation.
@misc{Weber2023ArXiv,
title = {A Mixed-Reality Dataset for Category-level 6D Pose and Size Estimation of Hand-occluded Containers},
author = {Weber, X. and Xompero, A. and Cavallaro, A.},
eprint={2211.10470},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2211.10470}
}
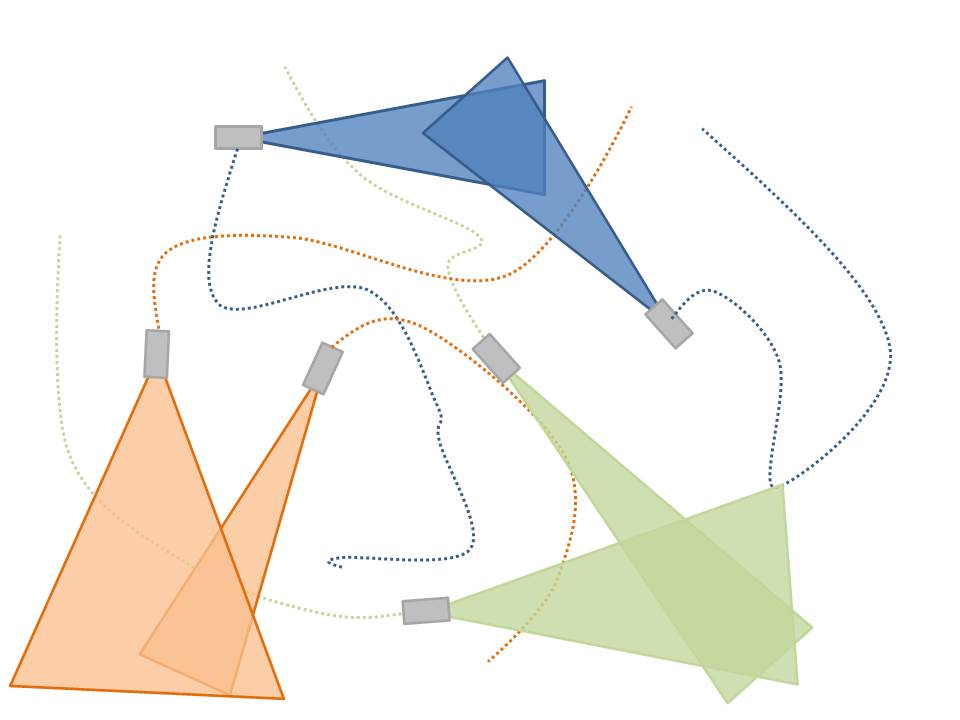
Local features for view matching across independently moving cameras
PhD Thesis, Queen Mary University of London, 2020
Supervisors:
Prof. Andrea Cavallaro, Queen Mary University of London, United Kingdom
Dr. Oswald Lanz, Fondazione Bruno Kessler, Italy
Examiners:
Dr. Stefan Leutenegger, Imperial College London, United Kingdom
Dr. Jean-Yves Guillemaut, University of Surrey, United Kingdom
Prof. Andrea Cavallaro, Queen Mary University of London, United Kingdom
Dr. Oswald Lanz, Fondazione Bruno Kessler, Italy
Examiners:
Dr. Stefan Leutenegger, Imperial College London, United Kingdom
Dr. Jean-Yves Guillemaut, University of Surrey, United Kingdom

ViProT: A Visual Probabilistic Model for Moving Interest Points Clusters Tracking
Master's Thesis, University of Trento, 2015
Advisors:
Dr. Nicola Conci, University of Trento, Italy
Dr. Radu Patrice Horaud, INRIA Grenoble Rhône-Alpes, France
Dr. Xavier Alameda-Pineda, INRIA Grenoble Rhône-Alpes, France
Dr. Sileye Ba, INRIA Grenoble Rhône-Alpes, France
Dr. Nicola Conci, University of Trento, Italy
Dr. Radu Patrice Horaud, INRIA Grenoble Rhône-Alpes, France
Dr. Xavier Alameda-Pineda, INRIA Grenoble Rhône-Alpes, France
Dr. Sileye Ba, INRIA Grenoble Rhône-Alpes, France