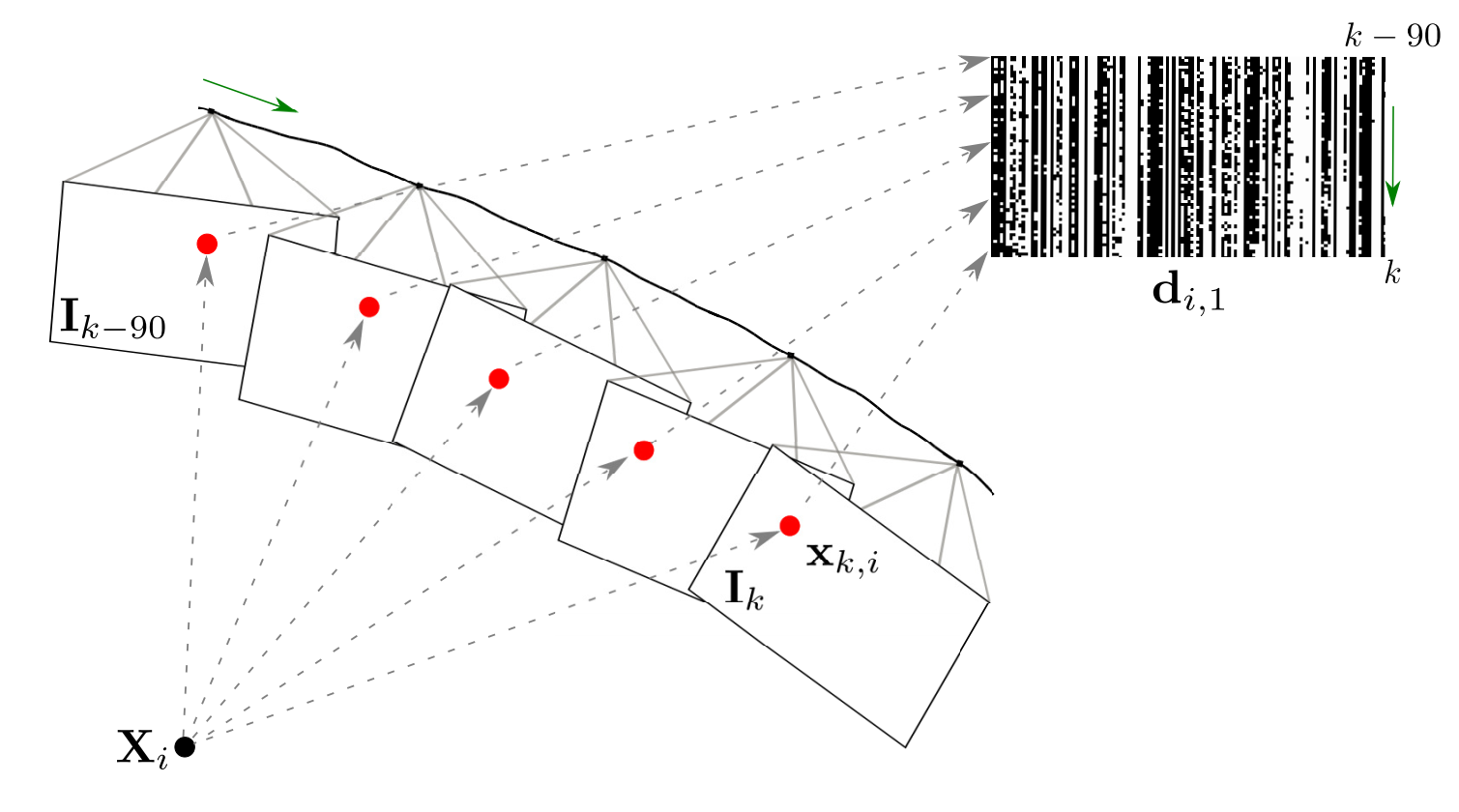
Dataset
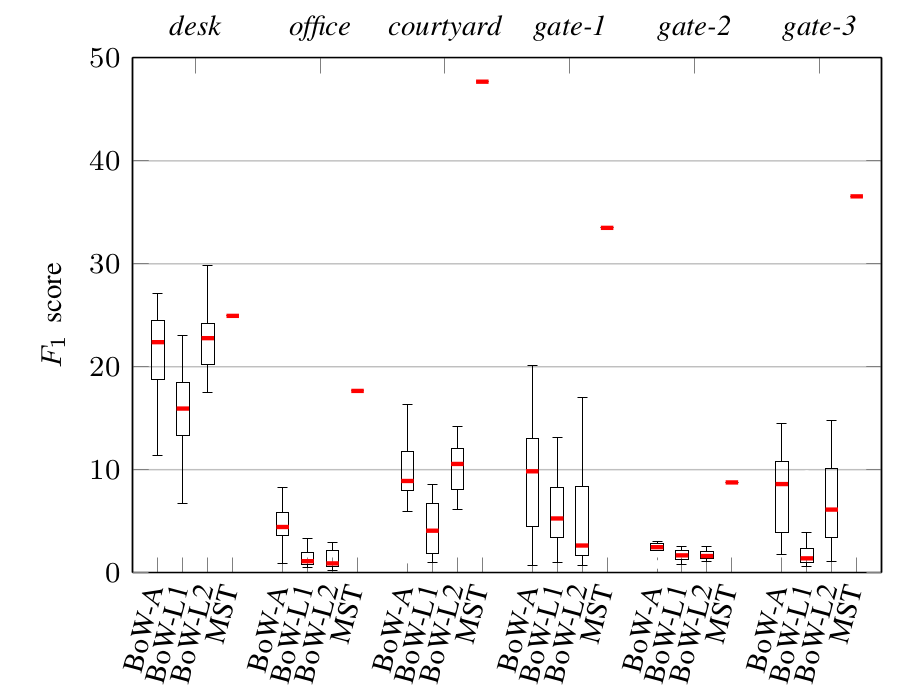
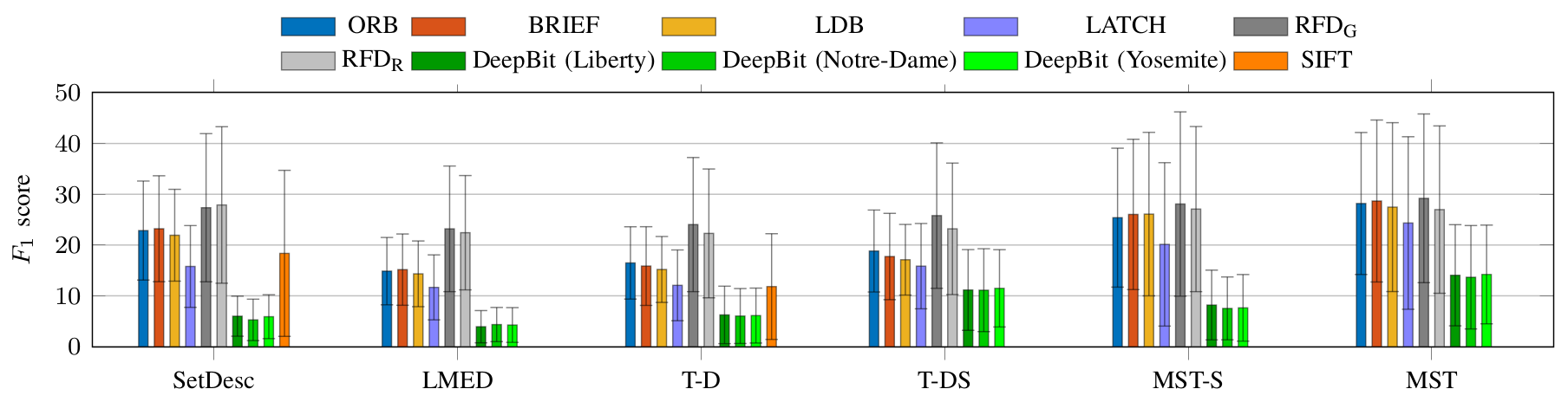
We use pairs of sequences, captured with hand-held cameras, from publicly available datasets: TUM-RGB-D SLAM; courtyard; and gate. From TUM-RGB-D SLAM we use two clips of 50 frames (640x480 pixels) with sufficient overlap from desk (with similar motion) and office (cameras move in opposite directions). From the first and fourth video of courtyard, we select the first 50 frames (800x450 pixels) after sub-sampling the videos from 50 to 25 fps. We select the first 100 frames (1280x720 pixels) of the four sequences of gate after down-sampling the video to 10 fps from 30 fps. We pair the first sequence with each of the other three sequences and we refer to each pair as gate-1, gate-2, gate-3, respectively.